 / Artykuły
/ środa, 14 stycznia 2026 roku
/ Artykuły
/ środa, 14 stycznia 2026 roku
CTRL + Grow Gdańsk 2026: miliony z contentu, AI bez złudzeń i SEO, które właśnie się zmienia

8 stycznia 2026 roku odbyło się wydarzenie CTRL + Grow, które bez przesady można uznać za jeden z najmocniejszych merytorycznie punktów na mapie branżowych spotkań SEM na początku roku. Nie była to konferencja o tym, że „AI zmienia SEO”, lecz rozmowa o tym, jak dokładnie je zmienia, gdzie realnie można na tym zarobić, a gdzie bardzo łatwo się sparzyć.
- Spis treści
- Michał Woroniecki – Jak zarobiłem kilka milionów na portalach contentowych?
- Jakub Dzikowski – Vibecoding w 2026 w SEO — szanse i zagrożenia
- Maciej Chmurkowski - Przestaw się albo zgiń. Dlaczego semantyczne SEO i AI to przyszłość marketingu?
- Tomasz Palak – Prawo i AI, czyli gdzie mogą być kłopoty
- Łukasz Kacprzak - Rok z GEO okiem produktowca
Na jednej scenie spotkali się praktycy contentu, technicznego SEO, prawa oraz product managementu, pokazując SEM z kilku perspektyw: od budowania i sprzedaży portali contentowych za miliony, przez wykrywanie footprintów AI i semantyczne SEO, aż po bardzo konkretne ryzyka prawne i produktowe związane z generatywną sztuczną inteligencją. Wspólny mianownik? Ewolucja SEO w kierunku encji, zaufania, autorów i relacji – nie fraz.
W tej relacji przechodzimy szczegółowo przez wszystkie prelekcje, cytując kluczowe tezy, procesy, narzędzia i case’y omawiane na scenie. Jeśli interesuje Cię:
- jak realnie monetyzować portale contentowe,
- dlaczego humanizacja treści AI to dziś wyścig zbrojeń,
- jak budować topical authority pod AI i LLM-y,
- gdzie prawo może zatrzymać Twoje działania szybciej niż update Google,
- oraz jak produktowo myśleć o SEO w erze GEO,
… to jesteś w dobrym miejscu. Poniżej znajdziesz konkrety, screeny, wnioski i pytania z sali, bez lania wody. Relacja jest skierowana do specjalistów SEO, którzy chcą rozumieć, co robić dalej, a nie tylko co się zmieniło.
Michał Woroniecki – Jak zarobiłem kilka milionów na portalach contentowych?
Prelegent zarysował swój model biznesowy jako oparty na rozbudowanej sieci portali contentowych, które pełnią przede wszystkim funkcję zaplecza pod sprzedaż publikacji sponsorowanych. To właśnie artykuły sponsorowane stanowią główne i najbardziej powtarzalne źródło przychodu w całym ekosystemie. Portale są projektowane i rozwijane w taki sposób, aby były atrakcyjne dla reklamodawców – zarówno pod kątem tematyki, jak i parametrów SEO.
Uzupełnieniem tego modelu jest flipowanie portali, czyli kupno istniejących serwisów, ich dalszy rozwój (content, linkowanie, poszerzanie tematyki), a następnie sprzedaż z zyskiem. Jak podkreślał prelegent, nie jest to działalność okazjonalna, lecz stały element strategii – część portali trafia docelowo na sprzedaż, inne pozostają w sieci i generują długofalowe przychody z publikacji.
Kolejnym filarem są domeny – zarówno ich przechwytywanie, jak i obrót. Domeny z historią stanowią bazę pod nowe projekty contentowe lub są sprzedawane jako samodzielne aktywa, jeśli ich potencjał rynkowy na to pozwala.
Istotnym kontekstem dla całej prelekcji było podkreślenie, że przez długi czas była to działalność jednoosobowa. Prelegent sam odpowiadał za rozwój portali, sprzedaż, kontakty z klientami i decyzje inwestycyjne. Dopiero wraz ze wzrostem skali pojawiła się potrzeba automatyzacji i stopniowego porządkowania procesów, co stało się punktem wyjścia do dalszych wątków omawianych w wystąpieniu.
Etapy rozwoju działalności i skala wzrostu
W kolejnej części prelekcji Michał Woroniecki przedstawił chronologiczny rozwój swojej działalności, pokazując, jak z dodatkowego źródła dochodu portale contentowe stały się głównym filarem biznesu.
Początki były bardzo skromne i opierały się na pierwszych sprzedażach publikacji sponsorowanych za kilkanaście–kilkadziesiąt złotych. Każda transakcja była raczej potwierdzeniem, że model w ogóle działa, niż realnym źródłem utrzymania. Z czasem – wraz z rozwojem portali i wzrostem ich parametrów – stawki za publikacje zaczęły systematycznie rosnąć, a przychody z tego źródła stały się zauważalnym dodatkiem do pensji z pracy etatowej.
Równolegle następowała rozbudowa zaplecza portali. Od kilku serwisów na początku, sieć stopniowo rosła do kilkunastu, następnie kilkudziesięciu projektów. Kluczowym momentem było przekroczenie skali, w której przychody z publikacji sponsorowanych stały się na tyle stabilne, że umożliwiły rezygnację z pracy etatowej i pełne skupienie się na własnej działalności.
Po przejściu na swoje tempo wzrostu jeszcze przyspieszyło. Liczba portali zwiększała się już nie liniowo, lecz skokowo, co bezpośrednio przełożyło się na przychody. W kolejnych latach sieć przekroczyła barierę stu portali, a sumaryczne wpływy z samych publikacji sponsorowanych – liczone bez sprzedaży portali i innych aktywności – sięgnęły kilku milionów złotych. Dane te miały charakter ilustracyjny i służyły pokazaniu skali oraz dynamiki wzrostu, a nie szczegółowemu rozliczeniu finansowemu.
Na tym etapie prelegent podkreślił, że wzrost nie był jednorazowym strzałem, lecz efektem konsekwentnego skalowania tego samego modelu – więcej portali, wyższa jakość, wyższe stawki i coraz większa powtarzalność przychodów.
Czynniki wpływające na wzrost przychodów
W tej części wystąpienia prelegent skupił się na tym, co realnie stało za wzrostem przychodów, podkreślając, że sama liczba portali nie była jedynym ani nawet najważniejszym czynnikiem.
Pierwszym i kluczowym elementem był systematyczny rozwój wiedzy SEO. Michał Woroniecki zwrócił uwagę, że moment wejścia do środowiska specjalistów i codzienny kontakt z bardziej doświadczonymi praktykami znacząco przyspieszył jego rozwój. Nowo zdobywana wiedza była od razu testowana i wdrażana na własnych portalach, co pozwalało szybko oceniać jej skuteczność w praktyce.
Drugim filarem była konsekwentna praca nad portalami. Prelegent zaznaczał, że wzrost nie wynikał z pojedynczych akcji, lecz z długotrwałej, regularnej pracy: publikowania treści, rozbudowy struktury serwisów oraz ich stopniowego wzmacniania. W początkowym okresie większość działań wykonywał samodzielnie, często kosztem czasu prywatnego, co – jak podkreślał – miało bezpośrednie przełożenie na tempo rozwoju projektów.
Istotną rolę odegrało również budowanie brandu, zarówno osobistego, jak i brandów poszczególnych portali. Obecność na wydarzeniach branżowych, nawiązywanie relacji oraz rozpoznawalność w środowisku SEO sprawiały, że portale były postrzegane jako bardziej wiarygodne, a sprzedaż publikacji sponsorowanych stawała się łatwiejsza i bardziej powtarzalna.
Wszystkie te działania prowadziły do systematycznego wzrostu jakości portali. Z czasem serwisy oferowały lepszy content, stabilniejsze parametry SEO i większą atrakcyjność dla reklamodawców, co pozwalało podnosić stawki i skalować przychody bez konieczności ciągłego zwiększania liczby projektów.
Koszty i optymalizacja działalności
Ten wątek pojawił się w prelekcji jako krótkie uzupełnienie obrazu biznesu, bez wchodzenia w szczegółowe wyliczenia. Prelegent zaznaczył, że głównym kosztem w całej działalności była przez długi czas produkcja treści, czyli copywriting na potrzeby rozbudowy portali. Wraz ze wzrostem skali zaczęło to generować istotne obciążenie finansowe.
Odpowiedzią na ten problem była automatyzacja tworzenia contentu oraz stopniowe ograniczanie zewnętrznych usług. Dzięki temu koszty jednostkowe spadały, a marżowość całego modelu rosła. Wspomniane zostały również standardowe wydatki na narzędzia SEO i linkowanie, potraktowane jednak wyłącznie jako element kontekstu kosztowego, a nie kluczowy temat prelekcji.
Flipowanie portali – mechanizm i przykład
W dalszej części prelekcji Michał Woroniecki przeszedł do konkretnego mechanizmu flipowania portali, pokazując ten proces na uproszczonym, ale liczbowo osadzonym przykładzie. Jak zaznaczał, schemat działania jest powtarzalny i opiera się na klasycznej zasadzie biznesowej: kupić możliwie tanio aktywo z potencjałem i zwiększyć jego wartość poprzez rozwój.
Proces zaczyna się od zakupu istniejącego portalu, który posiada już określone parametry SEO, historię domeny oraz pierwszą widoczność. Kluczowe jest to, że portal nie musi być w pełni wykorzystany – często są to projekty porzucone przez poprzednich właścicieli lub prowadzone bez jasno określonej strategii monetyzacji.
Po przejęciu serwisu następuje etap inwestycji w rozwój, obejmujący przede wszystkim:
- rozbudowę i uzupełnienie contentu,
- wzmocnienie profilu linkowego,
- rozszerzenie tematyki portalu, tak aby zwiększyć liczbę potencjalnych reklamodawców.
Dzięki temu portal zaczyna generować regularne przychody z publikacji sponsorowanych, jeszcze zanim trafi na sprzedaż. Ten etap jest istotny, ponieważ pozwala nie tylko odzyskać część zainwestowanych środków, ale też realnie podnosi wartość projektu w oczach potencjalnego kupca.
W przywołanym przykładzie prelegent pokazał, że po relatywnie niewielkim koszcie zakupu oraz dodatkowych inwestycjach w rozwój, portal w ciągu kilkunastu miesięcy wygenerował znaczące przychody bieżące, a następnie został sprzedany z wielokrotnym przebiciem względem ceny zakupu. Przykład ten miał podkreślić skalowalność modelu oraz to, że flipowanie nie jest jednorazowym strzałem, lecz elementem szerszej strategii zarządzania siecią portali.
Czynniki wpływające na sprzedaż portalu
Ten fragment prelekcji miał kluczowe znaczenie dla całego wystąpienia, ponieważ prelegent szczegółowo omówił elementy, które realnie decydują o tym, czy portal contentowy jest atrakcyjny dla kupującego i za jaką kwotę może zostać sprzedany.
Jednym z najważniejszych parametrów pozostaje DR (Domain Rating). Jak zaznaczał prelegent, mimo rosnącej świadomości rynku, w praktyce jest to nadal jeden z pierwszych wskaźników, na które zwracają uwagę potencjalni nabywcy i reklamodawcy. Wysoki DR ułatwia zarówno sprzedaż publikacji sponsorowanych, jak i późniejszą sprzedaż całego portalu, nawet jeśli inne elementy wymagają jeszcze dopracowania.
Równie istotna jest tematyka portalu. Prelegent wskazał, że nie wszystkie kategorie sprzedają się równie dobrze, a różnice potrafią być znaczące. Szczególną uwagę zwrócił na tematykę fotograficzną, która – jego zdaniem – cechuje się ponadprzeciętną atrakcyjnością sprzedażową. Wynika to z dużej liczby potencjalnych reklamodawców oraz szerokiego zastosowania linków w tym obszarze.
Kolejnym czynnikiem jest nazwa portalu, która powinna być możliwie spójna z jego tematyką. Portale o nazwach intuicyjnie kojarzących się z daną branżą są postrzegane jako bardziej wiarygodne i bezpieczne zakupowo. Element brandowy działa tu na korzyść sprzedającego – ułatwia negocjacje i skraca proces decyzyjny po stronie kupującego.
Duży nacisk został położony także na historię domeny (expirkę). Domeny z przeszłością, widocznością i istniejącym profilem linków mają wyraźną przewagę nad nowymi rejestracjami. Prelegent podkreślał, że w przypadku nowych domen trzeba liczyć się z naturalnym opóźnieniem – często rzędu 6–12 miesięcy – zanim portal zacznie realnie generować zainteresowanie i przychody. Domena z historią pozwala ten etap w dużej mierze ominąć, co znacząco zwiększa jej wartość rynkową.
W tym punkcie wyraźnie wybrzmiała teza, że sprzedaż portalu to nie suma przypadkowych parametrów, lecz efekt świadomego budowania aktywa pod kątem przyszłego nabywcy – od wyboru domeny, przez tematykę, aż po sposób rozwoju projektu.
Tematyki portali a potencjał sprzedażowy
W kolejnym punkcie prelegent rozszerzył wątek sprzedaży portali o zależność pomiędzy tematyką serwisu a jego potencjałem komercyjnym. Podkreślał, że nawet przy dobrych parametrach SEO różnice w sprzedawalności mogą być bardzo wyraźne w zależności od branży.
Do tematyk o najwyższym potencjale sprzedażowym zaliczył przede wszystkim szerokie kategorie lifestyle’owe, takie jak dom i ogród, moda czy technologia. Są one atrakcyjne dla reklamodawców, ponieważ umożliwiają naturalne osadzanie linków z wielu branż i dają dużą elastyczność w sprzedaży publikacji sponsorowanych.
Osobną kategorię stanowią portale lokalne. Mimo ograniczonego zasięgu często generują one stabilne zainteresowanie ze strony reklamodawców działających regionalnie. W ocenie prelegenta to segment wciąż niedoceniany, a jednocześnie relatywnie bezpieczny pod względem sprzedaży.
Z drugiej strony wskazał na tematyki wąskie i niszowe, takie jak rękodzieło, malarstwo, literatura czy bardzo specjalistyczne hobby. Tego typu portale mogą oczywiście generować przychody, jednak ich potencjał sprzedażowy jest zazwyczaj bardziej ograniczony i trudniejszy do skalowania. Jeszcze większe bariery pojawiają się w przypadku tematów silnie związanych ze światopoglądem, które – mimo ruchu i jakości treści – wzbudzają mniejsze zainteresowanie reklamodawców.
Ten fragment prelekcji miał na celu pokazanie, że dobór tematyki to decyzja stricte biznesowa, która powinna uwzględniać nie tylko SEO, ale również realny popyt na publikacje sponsorowane.
Znaczenie nazwy portalu
Michał Woroniecki zwrócił uwagę na rolę nazwy portalu jako czynnika wspierającego sprzedaż, zarówno pojedynczych publikacji sponsorowanych, jak i całego serwisu w procesie flipowania. Podkreślał, że nazwa – choć sama w sobie nie generuje przychodów – może istotnie ułatwiać lub utrudniać monetyzację.
Kluczowe znaczenie ma dopasowanie nazwy do tematyki portalu. Serwisy, których nazwa jednoznacznie komunikuje obszar tematyczny, są lepiej odbierane przez reklamodawców i budzą większe zaufanie. W praktyce przekłada się to na mniejszą liczbę pytań, krótszy proces decyzyjny oraz większą skłonność do zakupu publikacji.
Prelegent zaznaczył również, że element brandowy w nazwie działa na korzyść portalu, nawet jeśli nie jest to marka powszechnie rozpoznawalna. Sama spójność i logiczność nazwy sprawiają, że portal jest postrzegany jako bardziej profesjonalny i stabilny.
Jednocześnie wskazał, że słaba lub abstrakcyjna nazwa nie przekreśla możliwości zarabiania, ale zazwyczaj utrudnia sprzedaż i wymaga większego wsparcia innymi argumentami, takimi jak mocne parametry SEO czy atrakcyjna tematyka. Wystąpienie w tym punkcie pokazało, że nazwa portalu powinna być traktowana jako świadoma decyzja biznesowa.
Nowa domena vs domena z historią
Ten punkt prelekcji był jednym z najmocniej akcentowanych, ponieważ bezpośrednio dotyczył decyzji strategicznych przy budowie i sprzedaży portali contentowych. Prelegent wyraźnie zestawił ze sobą nowe domeny oraz domeny z historią, wskazując różnice w czasie, ryzyku i potencjale biznesowym.
W przypadku nowej domeny istotnym ograniczeniem jest czas. Michał Woroniecki podkreślał, że nawet przy poprawnie prowadzonym projekcie trzeba liczyć się z okresem rozruchu, który najczęściej wynosi od około 6 do nawet 12 miesięcy. W tym czasie portal wymaga inwestycji w content i linkowanie, ale nie generuje jeszcze realnego zainteresowania reklamodawców ani stabilnych przychodów. To oznacza zamrożenie kapitału i większą niepewność co do końcowego efektu.
Dodatkowo budowanie portalu od zera wiąże się z wyższym ryzykiem. Nowa domena nie posiada historii, profilu linkowego ani widoczności, co zwiększa zależność od kosztownych działań SEO i wydłuża drogę do momentu, w którym projekt staje się atrakcyjny sprzedażowo.
Na tym tle zdecydowanie lepiej wypadają domeny z historią. Prelegent zwrócił uwagę, że nawet jeśli domena była wcześniej wykorzystywana w innym celu, jej istniejąca historia, linki i często szczątkowa widoczność pozwalają znacznie szybciej wejść w etap monetyzacji. Taki portal może niemal od razu zacząć przyciągać zapytania o publikacje sponsorowane, a tym samym szybciej budować swoją wartość rynkową.
W tym fragmencie wyraźnie wybrzmiała teza, że domena z historią skraca drogę do zysków i obniża ryzyko inwestycyjne, a to czyni ją znacznie atrakcyjniejszą zarówno z perspektywy budowy portalu, jak i jego późniejszej sprzedaży.
Skala działalności i obecny model operacyjny
Na zakończenie prelegent krótko nakreślił obecną skalę działalności, podkreślając, że sieć obejmuje już dużą liczbę portali, zarządzanych w możliwie powtarzalnym i zautomatyzowanym modelu. Kluczowe procesy – od produkcji treści po obsługę publikacji sponsorowanych – zostały uporządkowane w taki sposób, aby nie wymagały ciągłego zaangażowania operacyjnego w każdy pojedynczy serwis.
Model ten pozwala utrzymywać stabilne, cykliczne przychody bez konieczności proporcjonalnego zwiększania nakładu pracy. Tym samym ten wątek stanowił naturalne domknięcie prelekcji, pokazując, że cała opisywana strategia prowadzi do skalowalnego i przewidywalnego biznesu opartego na portalach contentowych.
Jakub Dzikowski – Vibecoding w 2026 w SEO — szanse i zagrożenia
Jakub Dzikowski już na początku wystąpienia jasno określił ramy swojej prelekcji. Zamiast definiować genezę czy historię vibe codingu, przyjął perspektywę praktyka SEO, który traktuje to podejście jako sposób myślenia o budowaniu procesów i narzędzi, a nie jako osobny trend technologiczny. W jego ujęciu kluczowe nie jest to, jakiej technologii się używa, lecz jaki problem realnie rozwiązuje się po stronie biznesu.
Prelegent konsekwentnie akcentował, że w pracy SEO zbyt łatwo wpaść w pułapkę skupienia się na rozwiązaniach technicznych samych w sobie – frameworkach, modelach czy narzędziach – zamiast na potrzebach odbiorcy końcowego. Vibe coding w tej interpretacji oznacza koncentrację na szybkim dochodzeniu do sensownego efektu: znalezieniu wąskiego, ale istotnego problemu i dostarczeniu rozwiązania, które da się wytłumaczyć klientowi w kategoriach wartości, a nie architektury systemu.
W tym kontekście pojawiła się krótka, luźna wzmianka o inspiracji filmowej – jako metaforze podejścia problemowego, w którym najpierw rozumie się istotę wyzwania, a dopiero później dobiera narzędzia. Ten wątek pełnił rolę punktu wyjścia do dalszej narracji, ale nie był rozwijany – stanowił raczej ilustrację filozofii pracy, którą prelegent stosuje w praktyce.
Na tym etapie wystąpienia Dzikowski zarysował więc fundament całej prelekcji: odejście od myślenia technologia first na rzecz podejścia, w którym SEO, automatyzacja i AI są środkami do celu, a nie celem samym w sobie.
Kontekst doświadczeń i geneza narzędzi
W kolejnym fragmencie prelekcji Jakub Dzikowski przeszedł do konkretnych doświadczeń, które ukształtowały jego podejście do vibe codingu w praktyce. Punktem zwrotnym był udział w hackathonie Senuto, gdzie – mimo dostępu do rozbudowanego zespołu po stronie organizatora – szybko okazało się, że przewaga technologiczna nie zawsze decyduje o sukcesie projektu. W wielu zespołach nacisk położono na zaawansowanie techniczne rozwiązań, podczas gdy realne problemy branży i ich adresaci zeszli na dalszy plan.
Dzikowski, funkcjonując w roli zewnętrznego konsultanta SEO, musiał zmierzyć się z istotnym ograniczeniem zespołowym: do dyspozycji był tylko jeden programista. To wymusiło zmianę strategii – zamiast rywalizować technologią, konieczne było szybkie zidentyfikowanie problemu, który da się rozwiązać w formule MVP i który będzie miał realny potencjał biznesowy. Kluczowe stało się więc pytanie nie jak to zbudować, ale co faktycznie ma sens sprzedażowy i użytkowy.
Prelegent podkreślał, że właśnie w tym miejscu pojawia się istota jego podejścia: koncentracja na wartości, którą można jasno zakomunikować klientowi. Narzędzie, nawet proste technicznie, ma sens tylko wtedy, gdy odbiorca rozumie, co z niego wynika i jakie decyzje może na tej podstawie podjąć. W kontekście SEO oznacza to m.in. takie projektowanie procesów i automatyzacji, aby ich efekty dało się przełożyć na konkretne wnioski biznesowe, a nie wyłącznie na wskaźniki techniczne.
Ten etap prelekcji stanowił wyraźne przejście od filozofii do praktyki: od ogólnego myślenia problemowego do budowy narzędzi, które – mimo ograniczeń zasobowych – odpowiadają na realne potrzeby rynku i klientów.
Automatyzacja analiz SEO – narzędzia i procesy
W dalszej części prelekcji Jakub Dzikowski przeszedł do omówienia konkretnych rozwiązań automatyzujących analizy SEO, które powstały bezpośrednio z jego codziennej pracy z klientami. Punktem wyjścia były zadania powtarzalne, czasochłonne i trudne do przełożenia na jasny komunikat biznesowy – takie jak market share czy content gap – które często kończą się dla klienta zestawem arkuszy bez jednoznacznych wniosków.
Market share i content gap jako problem operacyjny
Prelegent opisał mechanizm, który polega na agregowaniu danych z arkuszy Senuto i ich dalszym przetwarzaniu w celu pokazania klientowi jego realnej pozycji rynkowej. Kluczowe było tu nie samo liczenie fraz czy wolumenów, ale stworzenie uproszczonego obrazu: estymowanego potencjału ruchu, udziału w rynku oraz obszarów, w których istnieje największa luka contentowa względem konkurencji. Tak przygotowane dane stanowiły punkt startowy do dalszych prac, zamiast kończyć się na klasycznym raporcie do interpretacji.
Ze względu na brak API oraz ograniczenia czasowe, Dzikowski zdecydował się na scraping danych bezpośrednio z arkuszy jako rozwiązanie kompromisowe. Podkreślał, że nie było to podejście idealne technologicznie, ale wystarczające, by szybko dostarczyć wartość i odpowiedzieć na pytanie klienta: gdzie jesteśmy na tle rynku i co możemy zyskać.
Interfejs i warstwa użytkowa
Uzupełnieniem procesu była prosta warstwa frontowa, umożliwiająca podgląd projektu, sortowanie keywordów i szybkie porównania z poszczególnymi konkurentami. Te elementy miały znaczenie drugorzędne, ale wzmacniały zrozumiałość analizy po stronie odbiorcy. Prelegent zaznaczył, że nawet bardzo proste narzędzia – o ile dobrze adresują problem – potrafią znacząco skrócić dystans komunikacyjny między specjalistą SEO a klientem.
Narzędzie do linkowania wewnętrznego
Kolejnym obszarem, który Jakub Dzikowski szczegółowo omówił, było automatyzowanie linkowania wewnętrznego, zadania powszechnie znanego jako czasochłonne i trudne do skalowania w większych serwisach. Prelegent zaznaczył, że impuls do stworzenia własnego narzędzia wynikał bezpośrednio z osobistych doświadczeń i strat czasowych, jakie generowało ręczne lub półautomatyczne mapowanie fraz do URL-i.
Podstawą działania narzędzia jest skrapowanie treści serwisu i jej wektoryzacja. Po odcięciu zbędnych elementów (żwiru w postaci stopki, powtarzalnych fragmentów czy elementów technicznych), treść jest porządkowana w taki sposób, aby nadawała się do dalszych obliczeń semantycznych. Następnie frazy kluczowe są mapowane do adresów URL na bazie podobieństwa wektorowego, z wykorzystaniem liczenia kosinusów, co pozwala wskazać najbardziej adekwatne miejsca do wstawienia linków.
Prelegent podkreślał, że sam mechanizm matematyczny nie jest niczym odkrywczym, natomiast realną wartość daje dopiero jego osadzenie w praktycznym procesie. Narzędzie działa na prostym modelu: arkusz z frazami, lista URL-i oraz warstwa obliczeniowa, która zwraca uporządkowane rekomendacje. Dzięki temu możliwe jest szybkie przejście od danych do decyzji operacyjnych, bez konieczności ręcznego przeglądania setek podstron.
Problemy techniczne i zastosowane obejścia
Istotną częścią tego wątku były problemy napotkane przy skalowaniu skrapowania. Dzikowski zwrócił uwagę na ograniczenia bibliotek typu Chrome for AI, które w teorii oferują wygodny dostęp do treści, ale w praktyce – przy większej liczbie requestów – potrafią zwracać puste lub niekompletne dane. Rozwiązaniem okazało się wdrożenie tzw. Emergency Fallback, czyli zapasowego mechanizmu opartego na Beautiful Soup i asynchronicznych zapytaniach HTTP.
To podejście, choć mniej eleganckie technologicznie, pozwoliło znacząco ograniczyć straty czasu i zwiększyć stabilność procesu. Wzmiankowo pojawił się także temat proxy i skalowania zapytań, jako elementu niezbędnego przy pracy na dużych serwisach.
Humanizacja treści – główny wątek prelekcji
Najważniejszą i najbardziej rozbudowaną częścią wystąpienia była humanizacja treści generowanych lub wspieranych przez AI. Jakub Dzikowski wyraźnie zaznaczył, że jego podejście nie polega na oszukiwaniu detektorów AI, lecz na realnej poprawie jakości tekstu. Punktem wyjścia było założenie, że jeśli treść jest logiczna, spójna i językowo poprawna, problem wykrywalności AI przestaje mieć znaczenie drugorzędne.
Prelegent podkreślał, że walka z checkerami AI jest z definicji skazana na frustrację. Brak transparentności algorytmów i częste zmiany powodują, że nawet drobna modyfikacja tekstu może diametralnie zmienić wynik. Zamiast tego zaproponował podejście systemowe: identyfikację powtarzalnych problemów językowych i strukturalnych, które obniżają jakość treści, niezależnie od tego, czy została ona napisana przez człowieka, czy przez model językowy.
Footprinty AI jako narzędzie diagnostyczne
Centralnym elementem tego podejścia są tzw. footprinty – zdefiniowane wzorce problemów występujących w tekstach. Dzikowski zidentyfikował 53 takie footprinty, z których każdy został opisany przy pomocy spójnej struktury: unikalnego ID, opisu problemu oraz przykładów pozytywnych i negatywnych. Każdy footprint był oparty na kilkudziesięciu rzeczywistych przykładach, co pozwalało uniknąć arbitralnych ocen.

Footprinty zostały pogrupowane w kategorie obejmujące m.in. logikę tekstu, gramatykę, słownictwo oraz znaczenie. Dzięki temu analiza nie sprowadzała się do powierzchownej oceny stylistycznej, lecz dotykała głębszych problemów, takich jak schematyczność zdań, nienaturalna rytmika czy powtarzalność konstrukcji typowych dla generacji AI.

Metodologia analizy i selekcja problemów
Proces identyfikacji problemów opierał się na wektoryzacji tekstu oraz analizie podobieństw z wykorzystaniem cosinusów i cross-encodera. Istotne było tu odseparowanie przykładów pozytywnych i negatywnych, co, jak zaznaczył prelegent w kontekście Q&A, nie było oczywiste na wczesnym etapie prac. Dopiero iteracyjne podejście pozwoliło ograniczyć liczbę fałszywych wskazań i skupić się na realnych problemach jakościowych.
W praktyce narzędzie nie próbowało poprawiać wszystkiego naraz. Analiza wskazywała konkretne fragmenty tekstu wraz z wyjaśnieniem, dlaczego dany element został zakwalifikowany jako problem. Dzięki temu humanizacja nie polegała na bezrefleksyjnej przeróbce treści, lecz na świadomej korekcie.
Rola modeli językowych w poprawkach
Do faktycznej poprawy tekstów Dzikowski wykorzystywał GPT-4o, który (po testach porównawczych) okazał się najbardziej relewantny w kontekście pracy na języku polskim. Model pełnił rolę narzędzia wykonawczego, a nie decyzyjnego: decyzja o tym, co jest problemem, zapadała wcześniej, na etapie analizy footprintów.
Jednocześnie prelegent jednoznacznie odciął się od korzystania z detektorów AI, zwłaszcza w wersjach obsługujących język polski. Wskazywał na fałszywie pozytywne wyniki oraz brak jasnej dokumentacji jako główne powody rezygnacji z tego typu narzędzi. W jego ocenie humanizacja ma sens tylko wtedy, gdy opiera się na mierzalnych i zrozumiałych kryteriach jakości, a nie na nieprzewidywalnych ocenach zewnętrznych systemów.
Ocena skuteczności checkerów AI
W kolejnej części prelekcji Jakub Dzikowski jednoznacznie odniósł się do tematu detektorów treści AI, traktując go jako istotne uzupełnienie wątku humanizacji. Jego stanowisko było klarowne: obecnie dostępne checkery nie stanowią wiarygodnego narzędzia oceny jakości treści, a ich stosowanie może prowadzić do błędnych wniosków i złych decyzji biznesowych.
Prelegent podkreślał, że w jego testach detektory AI nie wykazywały realnej skuteczności, szczególnie w przypadku języka polskiego. Wyniki były niestabilne, trudne do powtórzenia i często sprzeczne – ten sam tekst, po minimalnych zmianach lub nawet bez ingerencji, potrafił zostać oceniony skrajnie inaczej w krótkim odstępie czasu. Taka nieprzewidywalność całkowicie dyskwalifikuje checkery jako narzędzie operacyjne w pracy na większej skali.
Szczególną uwagę zwrócił na przypadki fałszywie pozytywnych wyników, m.in. w narzędziu Originality.ai. Teksty przygotowane świadomie, poprawne językowo i logicznie, bywały oznaczane jako wygenerowane przez AI, mimo że ich struktura i treść nie nosiły znamion automatyzacji. Problem ten był szczególnie widoczny w treściach eksperckich, nasyconych terminologią branżową, skrótami i precyzyjnym językiem technicznym.
Zdaniem Dzikowskiego detektory nie oferują żadnej transparentności co do kryteriów oceny – użytkownik nie wie, które elementy tekstu zostały uznane za problematyczne ani jak je poprawić. W efekcie praca z checkerami sprowadza się do walki z wynikiem, zamiast do realnej poprawy jakości treści. To właśnie ten brak informacji zwrotnej był jednym z głównych powodów, dla których prelegent całkowicie zrezygnował z ich stosowania na rzecz własnej metodologii opartej na footprintach i analizie lingwistycznej.
Przykłady i analizy empiryczne
Po omówieniu metodologii humanizacji treści Jakub Dzikowski przeszedł do przykładów empirycznych, które miały pokazać skalę problemu oraz praktyczne zastosowanie zaprezentowanego podejścia. Prelegent zaznaczył, że zależało mu nie na jednostkowych case’ach, lecz na pracy na dużym wolumenie danych, pozwalającym wyciągać powtarzalne wnioski.
Jednym z zaprezentowanych przykładów był pojedynczy footprint związany z tematyką fotograficzną. Na jego podstawie pokazano, w jaki sposób narzędzie identyfikuje konkretny problem językowy, przypisuje go do kategorii oraz generuje rekomendacje zmian. Ten fragment miał charakter ilustracyjny – jego celem było zobrazowanie mechanizmu działania, a nie szczegółowa analiza lingwistyczna.
Analiza Kozaczek.pl jako studium przypadku
Najbardziej rozbudowanym przykładem była analiza serwisu Kozaczek.pl. Dzikowski przeanalizował ponad sto tekstów, obejmujących łącznie około 3 milionów znaków. W ramach tej próby badawczej narzędzie zidentyfikowało 574 problemy jakościowe, co pozwoliło wyciągnąć wnioski dotyczące powtarzalności określonych błędów w skali całego portalu.
Prelegent zwrócił uwagę, że w przypadku serwisów o charakterze blogowym szczególnie często pojawiają się te same typy problemów: schematyczna logika tekstu, powtarzalność słów oraz uproszczone konstrukcje zdań. Na tej podstawie wyodrębniono listę dziesięciu najczęściej występujących problemów, które – zamiast rozpraszać uwagę na setki pojedynczych wskazań – stanowiły realny punkt zaczepienia do pracy redakcyjnej.
Wyniki analizy były eksportowane do arkusza, który pełnił rolę materiału roboczego dla copywritera. Dzięki temu humanizacja treści nie kończyła się na automatycznej ocenie, lecz stawała się wsparciem dla pracy manualnej, umożliwiając świadome poprawki bez ingerowania w warstwę faktograficzną tekstów.
Architektura i zaplecze techniczne
Po części poświęconej analizom empirycznym prelegent zarysował techniczne zaplecze narzędzia, podkreślając jednak, że architektura pełni tu rolę wspierającą, a nie dominującą. Centralnym elementem całego rozwiązania jest mechanizm RAG, który odpowiada za łączenie zidentyfikowanych problemów językowych z odpowiednimi przykładami, opisami i kontekstem potrzebnym do ich poprawy.
RAG został wykorzystany jako warstwa pośrednia pomiędzy analizą tekstu a generowaniem sugestii zmian. Dzięki temu narzędzie nie działa w trybie czarnej skrzynki, lecz opiera się na jasno zdefiniowanych danych wejściowych: footprintach, ich opisach oraz zbiorach przykładów pozytywnych i negatywnych. Taki model umożliwia kontrolę nad tym, co faktycznie wpływa na proces humanizacji i pozwala stopniowo rozwijać bazę wiedzy bez przebudowy całego systemu.
Od strony infrastrukturalnej dane przechowywane są w relacyjnej bazie PostgreSQL, która pełni funkcję magazynu zarówno dla tekstów, jak i metadanych związanych z footprintami oraz wynikami analiz. Prelegent wspomniał o tym rozwiązaniu jedynie kontekstowo, traktując je jako stabilne zaplecze, a nie kluczowy element przewagi.
Warstwa wizualna i dashboardowa została zbudowana w Lovable, co umożliwiło szybkie tworzenie interfejsów do przeglądania wyników analiz i pracy na tekście. Ten element został jedynie zasygnalizowany – jako przykład pragmatycznego podejścia, w którym narzędzia dobiera się pod kątem szybkości wdrożenia i użyteczności, a nie technologicznego prestiżu.
Dalszy rozwój narzędzia
W końcowej części merytorycznej prelekcji Jakub Dzikowski odniósł się do planów dalszego rozwoju zaprezentowanego narzędzia do humanizacji treści. Zaznaczył przy tym, że obecna wersja jest efektem iteracyjnej pracy i licznych testów, a nie zamkniętym, docelowym rozwiązaniem.
Jednym z kluczowych kierunków rozwoju ma być redukcja liczby footprintów. Prelegent przyznał, że obecny zestaw jest zbyt rozbudowany, a nie wszystkie zdefiniowane problemy występują w praktyce z podobną częstotliwością. Celem jest wyselekcjonowanie tych footprintów, które faktycznie wnoszą największą wartość jakościową i mają realny wpływ na odbiór tekstu.
Drugim istotnym obszarem jest kalibracja progów decyzyjnych oraz dalsza walidacja jakościowa. Dzikowski zwrócił uwagę, że obecne wartości progowe – oparte m.in. na podobieństwie wektorowym i cross-encoderze – wymagają dopracowania. W praktyce oznacza to ręczne przeglądy wyników, testowanie różnych ustawień oraz stopniowe dopasowywanie parametrów do rzeczywistych tekstów, zamiast polegania wyłącznie na automatycznych metrykach.
Wzmiankowo pojawił się również wątek rozwoju funkcji edukacyjnych, takich jak wewnętrzny czat. Jego rolą miałoby być nie tylko wskazywanie problemów, ale także tłumaczenie ich natury i kontekstu językowego, co mogłoby wspierać copywriterów i zespoły contentowe w długofalowej poprawie jakości treści. Ten element został jednak przedstawiony jako kierunek rozwojowy, a nie gotowe rozwiązanie.
Wnioski praktyczne i rekomendacje
W przedostatnim bloku merytorycznym Jakub Dzikowski zebrał dotychczasowe obserwacje w zestaw praktycznych wniosków, które można bezpośrednio zastosować w pracy z treściami SEO na dużą skalę. Kluczowym założeniem pozostaje humanizacja tekstu bez ingerencji w jego warstwę faktograficzną. Prelegent wielokrotnie podkreślał, że poprawa stylu, logiki i struktury nie może prowadzić do zmiany znaczeń, danych technicznych czy merytorycznych tez zawartych w treści.
Istotnym elementem rekomendowanego podejścia jest oparcie generacji i korekt na własnych danych, a nie na losowo scrapowanych źródłach z internetu. Dzikowski zwrócił uwagę, że praca na feedach produktowych, wewnętrznych bazach wiedzy czy własnym knowledge graphie znacząco ogranicza ryzyko halucynacji oraz niespójności z wizją biznesową klienta. Modele językowe powinny korzystać wyłącznie z tego, co zostało im świadomie dostarczone, zamiast dopowiadać brakujące informacje na podstawie ogólnej wiedzy.
W formie krótkich wskazówek operacyjnych prelegent odniósł się także do pracy na dużej skali treści. Zamiast próbować automatycznie poprawiać wszystko naraz, rekomendował selektywne podejście: wybór konkretnych kategorii problemów, iteracyjną analizę i stopniowe doskonalenie jakości. Taki model pozwala zachować kontrolę nad procesem, a jednocześnie realnie odciąża zespoły contentowe, zamiast generować kolejne warstwy technicznej złożoności.
Q&A – wątki merytoryczne
Ostatnia część prelekcji miała formę sesji pytań i odpowiedzi, w której Jakub Dzikowski doprecyzował kilka istotnych wątków pojawiających się wcześniej, szczególnie w kontekście dalszego rozwoju zaprezentowanego narzędzia.
Jednym z głównych tematów była potencjalna monetyzacja rozwiązania i możliwość przekształcenia go w model SaaS. Prelegent podszedł do tego zagadnienia ostrożnie, podkreślając, że na obecnym etapie priorytetem jest testowanie narzędzia w realnych projektach klienckich. Zwrócił uwagę na odpowiedzialność, jaka wiąże się z udostępnianiem narzędzia opartego na vibe codingu, oraz na potrzebę dalszego dopracowania mechanizmów przed ewentualnym skalowaniem i komercjalizacją.
W tym kontekście pojawiło się również pytanie o rolę programisty w dalszym rozwoju projektu. Dzikowski jednoznacznie zaznaczył, że mimo wykorzystania AI i podejścia low-code, pełnoprawny development jest niezbędny, jeśli narzędzie ma osiągnąć dojrzałość produktową. Wskazał, że wiele problemów ujawnia się dopiero na etapie iteracji, testów i optymalizacji – a ich rozwiązanie wymaga solidnych kompetencji programistycznych, wykraczających poza eksperymentalne prototypowanie.
Na koniec poruszono wątek konsultowania stylu tekstu i personalizacji językowej. Prelegent zaznaczył, że obecnie nie jest to priorytet, głównie ze względu na złożoność tematu i konieczność głębokiej wiedzy lingwistycznej. Traktował ten obszar raczej jako potencjalny kierunek rozwoju w przyszłości, po uprzednim uporządkowaniu kluczowych footprintów i osiągnięciu wysokiej powtarzalności jakościowej w procesie humanizacji.
Maciej Chmurkowski – Przestaw się albo zgiń. Dlaczego semantyczne SEO i AI to przyszłość marketingu?
Prelegent już na początku wystąpienia jasno zarysował główną tezę: klasyczne podejście oparte na frazach kluczowych przestaje być skuteczne w świecie zdominowanym przez modele językowe i semantyczne przetwarzanie treści. W jego ocenie fraza kluczowa pełni dziś co najwyżej rolę etykiety roboczej, natomiast nie jest nośnikiem znaczenia ani intencji użytkownika.
Maciej Chmurkowski konsekwentnie podkreślał, że zarówno wyszukiwarki, jak i systemy AI nie czytają tekstów przez pryzmat pojedynczych słów czy ich zagęszczenia, lecz analizują encje oraz relacje między nimi, osadzone w kontekście całej wypowiedzi. To właśnie encje (osoby, miejsca, organizacje, pojęcia czy zjawiska) stanowią podstawowy budulec znaczenia, a nie konkretne ciągi znaków wpisywane w pole wyszukiwania.
Zmiana paradygmatu ma istotne konsekwencje dla SEO i marketingu treści. Prelegent zwracał uwagę, że mechaniczne upychanie słów kluczowych może wręcz zaburzać semantykę tekstu i utrudniać jego poprawne zrozumienie przez modele językowe. W praktyce prowadzi to do sytuacji, w której treść jest gorzej interpretowana, mimo formalnego spełniania dawnych wytycznych optymalizacyjnych.
W nowym ujęciu kluczowe staje się projektowanie treści tak, aby w sposób spójny i kompletny opisywały dany obszar tematyczny: poprzez właściwy dobór encji, ich atrybutów oraz logicznych powiązań. To właśnie ten zestaw informacji pozwala algorytmom zrozumieć, o czym jest dana treść i jaką rolę pełni w szerszym kontekście wiedzy, a nie sama obecność określonych fraz.
Na tym etapie prelekcji autor wprowadził ramy koncepcyjne, które stanowią punkt wyjścia do dalszych, bardziej technicznych wątków związanych z NLP, grafami wiedzy i semantycznym planowaniem contentu.
Przetwarzanie języka naturalnego (NLP) jako fundament semantyki
W kolejnym kroku prelegent przeszedł do technicznych podstaw, które stoją za semantycznym rozumieniem treści, koncentrując się na procesach NLP wykorzystywanych przez wyszukiwarki i modele językowe. Jego celem było pokazanie, w jaki sposób tekst przechodzi drogę od surowego zapisu do struktury znaczeń możliwej do interpretacji przez algorytmy.
Proces ten rozpoczyna się od tokenizacji, czyli rozbicia tekstu na najmniejsze jednostki, które nie zawsze odpowiadają pełnym słowom. Zastosowanie technik subword pozwala modelom radzić sobie z odmianami, neologizmami i językami fleksyjnymi, co ma bezpośrednie przełożenie na jakość rozumienia treści.
Kolejnym etapem jest wektoryzacja, w której tokeny zamieniane są na reprezentacje liczbowe osadzone w wielowymiarowej przestrzeni. Dzięki temu możliwe staje się matematyczne określanie podobieństw i różnic znaczeniowych pomiędzy pojęciami. Prelegent obrazował ten mechanizm, wskazując, że semantycznie powiązane pojęcia znajdują się blisko siebie, podczas gdy te same słowa użyte w innym kontekście mogą być reprezentowane zupełnie inaczej.
Kluczowym elementem całego procesu jest jednak etap transformacji i analizy kontekstu, w którym model jednocześnie przetwarza wszystkie tokeny w zdaniu, badając relacje między nimi. To na tym poziomie następuje dynamiczne dopasowanie znaczenia – na przykład rozróżnienie, czy dane słowo odnosi się do produktu, marki czy obiektu fizycznego, w zależności od otoczenia językowego.
Uzupełnieniem tego mechanizmu jest rozpoznawanie encji (NER), czyli identyfikacja zdefiniowanych bytów oraz ich typów. Prelegent podkreślał, że to właśnie encje i relacje między nimi stanowią pomost pomiędzy NLP a budową grafów wiedzy. Zrozumienie tego procesu – jego zdaniem – fundamentalnie zmienia sposób patrzenia na tworzenie i ocenę treści, zarówno w SEO, jak i w kontekście wykorzystania ich przez systemy AI.
Encje i graf wiedzy jako rdzeń topical authority
W dalszej części prelekcji Maciej Chmurkowski przeszedł do zagadnienia encji jako fundamentu budowania topical authority, wyraźnie odcinając się od tradycyjnego myślenia w kategoriach pojedynczych tematów czy artykułów. W jego ujęciu to nie teksty same w sobie budują autorytet, lecz kompletna i logiczna sieć encji wraz z relacjami, które między nimi zachodzą.
Prelegent tłumaczył, że graf wiedzy powstaje w momencie, gdy w obrębie jednej dziedziny identyfikujemy wszystkie kluczowe encje oraz opisujemy ich wzajemne powiązania. Encje nie funkcjonują w izolacji – każda z nich coś opisuje, z czymś się łączy i do czegoś się odnosi. Dopiero pełne pokrycie istotnych bytów i relacji pozwala algorytmom uznać, że dany serwis rzeczywiście zna się na danym obszarze tematycznym.
W praktyce oznacza to odejście od selektywnego tworzenia treści pod pojedyncze zapytania na rzecz systemowego podejścia do tematu. Chmurkowski zwracał uwagę, że brak nawet pozornie drugorzędnych encji może powodować luki w grafie wiedzy, a tym samym osłabiać postrzeganą kompletność i wiarygodność treści. Topical authority nie wynika więc z liczby artykułów, lecz z jakości i pełności reprezentacji wiedzy.
Graf wiedzy – jak podkreślał – powinien być punktem wyjścia do planowania contentu. Dopiero po jego zbudowaniu sensowne staje się tworzenie poszczególnych materiałów, które w naturalny sposób wypełniają kolejne fragmenty grafu. Takie podejście porządkuje proces tworzenia treści i jednocześnie zwiększa szanse, że zarówno wyszukiwarki, jak i systemy AI będą w stanie skutecznie wykorzystać publikowane materiały jako źródło wiedzy.
Zaufanie (Trust) jako czynnik selekcji treści
W kolejnej części wystąpienia Maciej Chmurkowski skupił się na zaufaniu jako kluczowym filtrze decydującym o tym, które treści są wykorzystywane i cytowane przez systemy AI. Podkreślał, że w świecie semantycznego SEO samo dopasowanie tematyczne przestaje wystarczać – równie istotna staje się możliwość weryfikacji i przeliczenia treści przez algorytmy.
Prelegent wskazywał kilka powtarzalnych elementów, które budują trust. Jednym z nich jest obecność źródeł i bibliografii, które sygnalizują, że treść nie powstała w próżni i opiera się na istniejącej wiedzy. Równie ważne są dane liczbowe oraz fakty, które – jak zaznaczał – w dużej mierze wynikają bezpośrednio z poprawnie zdefiniowanych encji i relacji między nimi. Dzięki temu modele językowe mogą łatwiej identyfikować informacje jako sprawdzalne i spójne.
Istotnym aspektem zaufania jest również brak sprzeczności z konsensusem, czyli niesprzeciwianie się powszechnie przyjętym faktom i ustaleniom. Chmurkowski odwoływał się tu do mechanizmów oceny treści, które mają eliminować informacje jawnie błędne lub kontrowersyjne wbrew aktualnej wiedzy. Treści odbiegające od konsensusu – nawet jeśli są rozbudowane i technicznie poprawne – mogą być pomijane w odpowiedziach generowanych przez AI.
Prelegent zwrócił także uwagę na aspekt techniczny zaufania, czyli łatwość przetwarzania treści. Strony przeładowane kodem, rozbudowanym JavaScriptem czy nadmiernie skomplikowaną strukturą HTML utrudniają ekstrakcję kluczowych informacji. W praktyce lepiej radzą sobie materiały krótsze, konkretne i logicznie uporządkowane, w których hierarchia informacji jest czytelna już na pierwszy rzut oka.
W tym ujęciu trust przestaje być pojęciem wyłącznie jakościowym, a staje się cechą operacyjną: treści godne zaufania to takie, które są spójne semantycznie, zgodne z faktami i możliwe do szybkiego oraz jednoznacznego przetworzenia przez systemy AI.
Query fan-out – dekonstrukcja zapytań
Kolejnym kluczowym zagadnieniem poruszonym w prelekcji był mechanizm query fan-out, który – zdaniem Macieja Chmurkowskiego – najlepiej obrazuje, dlaczego myślenie w kategoriach pojedynczych słów kluczowych jest dziś niewystarczające. Prelegent wyjaśniał, że współczesne systemy wyszukiwania nie pracują na zapytaniu w jego pierwotnej, uproszczonej formie, lecz automatycznie rozbijają je na zestaw powiązanych encji, tematów i pytań pomocniczych.
W praktyce oznacza to, że jedno zapytanie użytkownika uruchamia cały wachlarz podzapytań semantycznych, które obejmują różne aspekty tematu: definicje, zależności, procesy, zastosowania czy kontekstowe problemy poboczne. Modele językowe generują ten rozsiew zapytań na podstawie relacji między encjami, a nie na podstawie synonimów czy odmian fraz.
Prelegent podkreślał, że zrozumienie query fan-out diametralnie zmienia sposób planowania treści. Skuteczny content nie powinien odpowiadać na jedno, główne pytanie, lecz pokrywać pełen zestaw zagadnień, które algorytmy uznają za istotne w danym kontekście. Brak odpowiedzi na część z tych podzapytań powoduje, że treść jest postrzegana jako niekompletna, nawet jeśli formalnie dotyczy właściwego tematu.
W tym ujęciu query fan-out staje się naturalnym przedłużeniem grafu wiedzy. Mając zdefiniowane encje i relacje, łatwiej przewidzieć, jakie pytania i wątki będą rozwijane przez algorytmy. Dzięki temu planowanie contentu przestaje opierać się na intuicji lub narzędziach stricte keywordowych, a zaczyna być procesem logicznym, opartym na strukturze znaczeń i intencjach użytkowników.
Struktura treści i BLUF (Bottom Line Up First)
Następnie prelegent przeszedł do zagadnienia struktury treści, wskazując BLUF jako jeden z kluczowych elementów dostosowania contentu do sposobu, w jaki przetwarzają go modele językowe. Zasada Bottom Line Up First polega na umieszczaniu najważniejszych informacji już na początku tekstu, zamiast stopniowego dochodzenia do sedna, charakterystycznego dla klasycznych form publicystycznych.
Maciej Chmurkowski zwracał uwagę, że zarówno wyszukiwarki, jak i systemy AI dążą do jak najszybszego potwierdzenia, czy dana treść odpowiada na intencję zapytania. Pierwszy akapit nie powinien więc pełnić roli ogólnego wstępu ani narracyjnego wprowadzenia, lecz stanowić syntetyczną odpowiedź na kluczowe pytania: czego dotyczy treść, jaki problem rozwiązuje i w jakim zakresie.
Takie wczesne potwierdzenie ma znaczenie nie tylko semantyczne, ale również operacyjne. Modele językowe, analizując treść fragmentami, w pierwszej kolejności skupiają się na górnych partiach tekstu. Jeżeli tam nie znajdują relewantnych informacji, dalsze sekcje mogą w ogóle nie zostać wykorzystane lub zinterpretowane jako mniej istotne.
W dalszej części tekstu – zgodnie z BLUF – powinny pojawiać się stopniowo bardziej szczegółowe informacje, a na końcu treści uzupełniające lub kontekstowe. Taka hierarchia sprzyja zarówno czytelności dla użytkownika, jak i efektywności przetwarzania przez AI, które łatwiej wyodrębnia logiczne bloki wiedzy i przypisuje im odpowiednie znaczenie.
Spójność semantyczna i similarity score
W dalszej części prelekcji Maciej Chmurkowski skupił się na zagadnieniu spójności semantycznej treści, pokazując, w jaki sposób można ją mierzyć i wykorzystywać w praktyce. Kluczowym pojęciem był tu similarity score, czyli miara podobieństwa semantycznego pomiędzy fragmentami tekstu a całością materiału lub jego głównym tematem.

Prelegent wyjaśniał, że treść nie powinna być analizowana wyłącznie jako jeden blok. Znacznie skuteczniejsze jest dzielenie jej na mniejsze jednostki – na przykład sekcje wyznaczone przez nagłówki H2 – i porównywanie ich wektorowych reprezentacji z wektorem całego artykułu lub zdefiniowanego tematu. Dzięki temu można precyzyjnie ocenić, które fragmenty są semantycznie spójne, a które odbiegają od głównego wątku.
Podstawą takich analiz jest obliczanie podobieństwa wektorów, najczęściej za pomocą miary cosinusowej. Im wyższy wynik similarity score, tym mniejszy kąt znaczeniowy pomiędzy porównywanymi fragmentami. W praktyce pozwala to zidentyfikować sekcje, które są słabo powiązane z tematem artykułu, zawierają dygresje lub wprowadzają treści trudne do powiązania z resztą materiału.
Chmurkowski podkreślał, że niski similarity score nie zawsze oznacza konieczność usunięcia fragmentu. Często jest to sygnał, że dana sekcja wymaga doprecyzowania, uzupełnienia encji lub lepszego osadzenia w kontekście całego tekstu. Takie podejście pozwala świadomie poprawiać jakość treści, zamiast opierać się wyłącznie na intuicji redakcyjnej.
W tym ujęciu similarity score staje się narzędziem kontroli jakości semantycznej – zarówno dla SEO, jak i pod kątem wykorzystania treści przez systemy AI. Spójne semantycznie materiały są łatwiejsze do przetworzenia, lepiej rozumiane przez modele językowe i częściej wykorzystywane jako wiarygodne źródło informacji.
Proces generowania treści – autorski case
W dalszej części prelekcji Maciej Chmurkowski krótko odniósł się do autorskiego procesu generowania treści, który wykorzystuje w praktyce. Zaznaczał przy tym, że nie chodzi o pojedyncze narzędzie czy prompt, lecz o uporządkowany pipeline, oparty na wcześniejszych elementach: semantyce, encjach, grafie wiedzy oraz intencji zapytania.
Proces rozpoczyna się od zrozumienia intencji i charakteru zapytania, a następnie od jego semantycznej klasyfikacji. Prelegent podkreślał, że analiza wyników wyszukiwania i dominującego typu treści jest niezbędna, aby nie tworzyć materiału oderwanego od realnych oczekiwań użytkowników i algorytmów. Dopiero na tej podstawie następuje rozbicie tematu na podzapytania oraz zebranie faktów, encji i danych – najlepiej z różnych źródeł, niekoniecznie powielanych przez konkurencję.
Kolejnym etapem jest budowa grafu wiedzy i określenie relacji między encjami, co pozwala zaplanować strukturę treści oraz poziom szczegółowości poszczególnych sekcji. Dopiero na tym etapie powstaje właściwy tekst, który następnie jest weryfikowany pod kątem spójności semantycznej, czytelności i ludzkiego stylu.
Chmurkowski zwracał uwagę, że taki proces jest znacznie bardziej czasochłonny i kosztowny niż masowa produkcja treści, ale efekt końcowy jest nieporównywalnie lepszy. W jego ocenie to właśnie tego typu podejście będzie w przyszłości standardem dla treści, które mają realnie konkurować o widoczność i wykorzystanie przez systemy AI.
Wnioski końcowe
W finalnej części prelekcji Maciej Chmurkowski spiął wszystkie wcześniejsze wątki w spójny obraz zmiany, z jaką musi zmierzyć się branża SEO i marketingu treści. Podkreślał, że semantyka, encje oraz zaufanie tworzą dziś fundament skutecznej obecności w ekosystemie wyszukiwarek i systemów AI. To one decydują o tym, czy treść zostanie poprawnie zrozumiana, uznana za wiarygodną i realnie wykorzystana w odpowiedziach generowanych przez modele językowe.
W tym ujęciu marketing treści przestaje być grą o widoczność pojedynczych fraz, a staje się procesem modelowania wiedzy: od grafów encji, przez kompletność tematyczną, po strukturę i hierarchię informacji. Prelegent zaznaczał, że jest to kierunek nie tyle opcjonalny, co nieunikniony – szczególnie w kontekście rosnącej roli AI jako pośrednika między użytkownikiem a treścią.
Na sam koniec pojawiła się krótka, symboliczna klamra całego wystąpienia: konieczność przestawienia się. Nie była ona jednak przedstawiona jako hasło alarmistyczne, lecz jako logiczna konsekwencja zmian technologicznych. Zdaniem Chmurkowskiego ci, którzy odpowiednio wcześnie dostosują sposób myślenia o treści do realiów semantycznych i AI, zyskają trwałą przewagę nad tymi, którzy pozostaną przy dawnych schematach.
Sesja Q&A
W końcowej części prelekcji, w ramach sesji pytań i odpowiedzi, pojawiło się kilka istotnych wątków praktycznych, które doprecyzowały wcześniejsze tezy. Jednym z nich była kwestia modeli embeddingów wykorzystywanych do analiz semantycznych. Prelegent przyznał, że systemy takie jak Google czy duże modele językowe korzystają z własnych, zamkniętych rozwiązań, jednak w praktyce narzędzia oparte na dostępnych embeddingach dają wystarczająco zbliżone wyniki, aby sensownie wspierać proces tworzenia i oceny treści.
Dużo uwagi poświęcono również znaczeniu Schema.org w kontekście AI. Chmurkowski podkreślał, że choć dane strukturalne mogą mieć wartość pomocniczą w klasycznym SEO, to w przypadku odpowiedzi generowanych przez AI ich wpływ jest znikomy lub żaden. W jego obserwacjach treści cytowane przez systemy AI nie różniły się pod tym względem od treści niecytowanych, co podważa sens traktowania schemy jako czynnika decydującego o widoczności w odpowiedziach AI.
Najmocniej zaakcentowanym wątkiem była jednak authority autora. Prelegent wskazywał, że rozpoznawalność i wiarygodność autora stają się jednym z kluczowych sygnałów zaufania, szczególnie w branżach wrażliwych lub konkurencyjnych. Przywoływał przykład projektu realizowanego na rynku zagranicznym, w którym budowa sieci autorów – oparta na ich realnej obecności w mediach społecznościowych, linkowaniu i konsekwentnej aktywności – przełożyła się na wyraźny wzrost widoczności i cytowalności treści.
Wnioski z tej części były jednoznaczne: w semantycznym SEO coraz trudniej oddzielić treść od jej autora. Autorytet nie jest już wyłącznie cechą domeny czy profilu linkowego, lecz wynikiem spójnego ekosystemu sygnałów, które potwierdzają, że za publikowanymi treściami stoi realna, wiarygodna ekspertyza.
Tomasz Palak – Prawo i AI, czyli gdzie mogą być kłopoty
Prelegent rozpoczął od zwrócenia uwagi na pozornie martwe zapisy umowne, które w kontekście AI zyskują zupełnie nowe znaczenie. Jednym z nich jest klauzula zobowiązująca do osobistego wykonania umowy. W tradycyjnym ujęciu miała ona zapobiegać przekazywaniu zlecenia innym osobom – np. podwykonawcom, asystentom czy stażystom. W realiach narzędzi generatywnych taka klauzula może jednak zostać zinterpretowana znacznie szerzej.
Tomasz Palak podkreślał, że jeżeli umowa przewiduje osobiste wykonanie usługi, to użycie AI jako faktycznego zastępcy człowieka może zostać uznane za jej naruszenie. Kluczowe nie jest tu samo wspomaganie się narzędziem, ale stopień, w jakim AI przejmuje wykonanie istotnej części zobowiązania. W przykładzie prelegenta – wysłanie nagrania lub wygenerowanej prezentacji zamiast osobistego wystąpienia – problem nie dotyczy technologii jako takiej, lecz niespełnienia oczekiwanego świadczenia.
Istotnym wątkiem było również to, że wiele takich zapisów funkcjonuje w umowach od lat i często bywa pomijanych przy ich analizie. Dopiero nowe technologie sprawiają, że strony zaczynają czytać je na nowo. Analogicznie jak klauzule dotyczące siły wyższej czy epidemii, które długo wydawały się czysto teoretyczne, dziś zapisy o osobistym wykonaniu umowy mogą stać się podstawą realnych sporów.
Prelegent wyraźnie zaznaczył, że nie mamy tu do czynienia z żadną luką prawną. Prawo nie nie nadąża za AI – raczej stare regulacje są adaptowane do nowych zastosowań. To oznacza, że odpowiedzialność może wynikać nie z samego faktu użycia AI, lecz z kolizji tego użycia z istniejącymi zobowiązaniami umownymi. W praktyce oznacza to konieczność uważniejszego audytu umów – szczególnie tam, gdzie AI zaczyna odgrywać realną rolę w procesie realizacji usług.
Prawo nie nadąża vs. adaptacja istniejących przepisów
W dalszej części tego wątku Tomasz Palak odniósł się do często powtarzanego argumentu, że prawo nie nadąża za rozwojem AI. Zwrócił uwagę, że z perspektywy praktyki prawniczej jest to uproszczenie, które może być wręcz mylące. W rzeczywistości w zdecydowanej większości przypadków nie mamy do czynienia z próżnią prawną, lecz z próbą stosowania istniejących regulacji do nowych narzędzi i modeli działania.
Prelegent podkreślał, że prawo od lat funkcjonuje w ten sam sposób wobec kolejnych nowych technologii – zmieniają się narzędzia, natomiast mechanizmy oceny pozostają podobne. Kluczowe jest nie to, czy dana czynność została wykonana z użyciem AI, lecz jaki jest jej efekt prawny i czy mieści się on w granicach już obowiązujących norm. Sądy i prawnicy nie pytają więc, czym coś zostało zrobione, ale co zostało zrobione i jakie skutki to wywołuje.
W tym kontekście AI nie jest traktowane jako rewolucja wymagająca zupełnie nowych przepisów w każdej dziedzinie, lecz jako kolejny sposób realizacji działań, które prawo już potrafi oceniać. Stare regulacje – często niedoceniane lub ignorowane – zyskują drugie życie i zaczynają być interpretowane w świetle nowych realiów technologicznych. Dla praktyków oznacza to konieczność zmiany perspektywy: zamiast czekać na nowe ustawy, warto dokładnie przyjrzeć się temu, jak istniejące przepisy mogą zostać zastosowane do pracy z AI.
Kryterium podobieństwa w ocenie naruszeń
Przechodząc do zagadnień związanych z prawem autorskim, Tomasz Palak mocno zaakcentował jedną podstawową zasadę: w ocenie potencjalnego naruszenia nie ma znaczenia, czy dany materiał został stworzony przez człowieka czy wygenerowany przez AI. Z punktu widzenia prawa narzędzia są irrelewantne – kluczowy jest wyłącznie efekt końcowy i jego podobieństwo do chronionego pierwowzoru.
Prelegent wskazywał, że to częsty błąd w myśleniu użytkowników AI: skupianie się na samym fakcie użycia algorytmu, zamiast na rezultacie, który trafia na rynek. W praktyce sądowej pytanie zawsze brzmi: czy nowy materiał przejmuje zbyt wiele cech chronionego utworu. Jeżeli odpowiedź jest twierdząca, fakt, że powstał on w wyniku promptu, a nie pracy grafika czy copywritera, nie stanowi żadnej linii obrony.
Na przykładach wizualnych Palak pokazywał, że podobieństwo nie jest oceniane zero-jedynkowo. Analizuje się całość wrażenia: kompozycję, charakterystyczne elementy, układ postaci czy motywów. W tym sensie AI nie rozmywa odpowiedzialności – przeciwnie, może ją uwypuklać, jeśli generowany materiał zbyt wyraźnie przypomina konkretne, istniejące dzieło.
Istotnym wnioskiem z tej części prelekcji było podkreślenie, że prawo nie interesuje się procesem twórczym, lecz jego rezultatem. To oznacza, że każdy materiał wygenerowany z użyciem AI powinien być oceniany tak samo, jak treść wykonana w pełni manualnie – pod kątem stopnia podobieństwa i potencjalnego naruszenia cudzych praw.
Granica dopuszczalnej inspiracji
Jednym z kluczowych momentów prelekcji było omówienie granicy między inspiracją a plagiatem, którą – jak podkreślał Tomasz Palak – w praktyce wyznacza nie deklaracja twórcy, lecz ocena efektu końcowego. Inspiracja sama w sobie jest dopuszczalna, ale tylko do momentu, w którym dochodzi do tzw. wystarczającego przekształcenia pierwotnego materiału.
Prelegent odwoływał się do konkretnych rozstrzygnięć sądowych, w których w ramach jednej sprawy część prac została uznana za naruszające prawa autorskie, a część nie. Ten sam autor, ten sam kontekst, a jednak odmienne oceny – co dobrze pokazuje, że granica nie przebiega na poziomie intencji, lecz zakresu przejętych elementów. Sąd analizuje m.in. kompozycję, liczbę zapożyczonych motywów, ich rozpoznawalność oraz to, czy nowa praca wnosi własną, autonomiczną wartość twórczą.
Palak zwracał uwagę, że samo przemalowanie lub kosmetyczne zmiany nie wystarczają. Dopiero sytuacja, w której dodane zostają nowe elementy, zmienia się układ, narracja lub znaczenie całości, może pozwolić mówić o twórczym przekształceniu. To właśnie ten moment – trudny do opisania jednym przepisem – decyduje o tym, czy dana inspiracja mieści się jeszcze w granicach prawa.
Istotne było również podkreślenie, że narzędzie nie ma żadnego znaczenia dla tej oceny. To, czy dany materiał został wygenerowany przez AI, czy stworzony manualnie, nie wpływa na kwalifikację prawną. Jeżeli efekt końcowy przejmuje zbyt wiele z konkretnego pierwowzoru, ryzyko naruszenia pozostaje takie samo. W praktyce oznacza to konieczność krytycznej oceny wygenerowanych treści – zwłaszcza wtedy, gdy wyraźnie ciągną w stronę jednego, łatwo rozpoznawalnego źródła.
Cytaty i nawiązania popkulturowe
Uzupełniając wątek inspiracji, Tomasz Palak odniósł się do krótkich cytatów i rozpoznawalnych odniesień popkulturowych, które często pojawiają się w treściach marketingowych – również tych tworzonych lub wspieranych przez AI. Zwrócił uwagę, że prawo dopuszcza tego typu zabiegi, ale ich legalność zawsze zależy od kontekstu użycia.
Prelegent wskazywał, że sądy akceptują krótkie, charakterystyczne frazy czy skojarzenia znane z filmów, seriali lub piosenek, o ile pełnią one rolę aluzji, a nie substytutu oryginalnego utworu. Kluczowe jest to, by taki element był jedynie dodatkiem do własnej kreacji, a nie jej osią konstrukcyjną. Inaczej mówiąc – cytat może funkcjonować jako rozpoznawalny mrugnięcie okiem do odbiorcy, ale nie powinien przejmować ciężaru przekazu.
Jednocześnie Palak podkreślał, że reklama jest obszarem podwyższonego ryzyka. To, co w treści redakcyjnej lub humorystycznej może zostać uznane za dopuszczalne nawiązanie, w komunikacji stricte sprzedażowej bywa oceniane znacznie ostrzej. Ten sam zwrot czy motyw, użyty w innym celu i kontekście, może prowadzić do zupełnie odmiennych konsekwencji prawnych.
W praktyce oznacza to, że generując treści – niezależnie od tego, czy robi to człowiek, czy AI – warto analizować nie tylko samą formę nawiązania, ale także miejsce i funkcję, jaką pełni ono w komunikacji. To właśnie kontekst, a nie sam fakt cytowania czy inspiracji, decyduje o tym, czy dana treść mieści się w bezpiecznych granicach prawa.
Mała baza treningowa jako źródło zwiększonego ryzyka podobieństwa
Rozpoczynając wątek danych treningowych, Tomasz Palak zwrócił uwagę na często pomijany, a istotny czynnik ryzyka: wielkość i różnorodność bazy, na której model został wytrenowany. Im mniejsza baza źródłowa, tym większe prawdopodobieństwo, że wygenerowany efekt będzie zbyt mocno przypominał konkretny, istniejący materiał.
Prelegent ilustrował ten problem na przykładach sytuacji, w których AI zna dany motyw wyłącznie z jednego lub bardzo ograniczonego zbioru danych – pojedynczego zdjęcia, unikalnej ilustracji czy jednego artykułu. W takim scenariuszu model nie ma realnej przestrzeni do syntezy i uogólnienia wzorców, przez co ryzyko niezamierzonego odtworzenia cech pierwowzoru gwałtownie rośnie. Z punktu widzenia prawa nie ma tu znaczenia, że podobieństwo powstało automatycznie – liczy się fakt, że efekt końcowy może być rozpoznawalny jako wtórny wobec konkretnego źródła.
Palak podkreślał, że to właśnie małe, niszowe zbiory danych są szczególnie problematyczne. W przeciwieństwie do motywów powszechnych, obecnych w tysiącach wariantów, unikalne materiały nie rozmywają się statystycznie. Jeżeli AI zostało nakarmione bardzo wąskim zestawem treści, użytkownik musi liczyć się z tym, że wygenerowany rezultat może zostać uznany za zbyt podobny – nawet jeśli nie było takiej intencji.
W praktyce oznacza to, że ryzyko prawne nie zawsze rośnie wraz z poziomem zaawansowania narzędzia. Paradoksalnie może być ono większe tam, gdzie baza treningowa jest uboga lub jednorodna, a wygenerowany materiał łatwo skojarzyć z jednym, konkretnym źródłem.
Celebryci i osoby rozpoznawalne – ryzyko naruszeń wizerunku i głosu
Kontynuując temat danych treningowych, Tomasz Palak zwrócił szczególną uwagę na osoby publiczne i łatwo rozpoznawalne, które stanowią jedną z najbardziej ryzykownych kategorii przy pracy z AI. Chodzi nie tylko o wizerunek wizualny, ale również o charakterystyczny głos, sposób mówienia czy inne cechy identyfikujące konkretną osobę.
Prelegent podkreślał, że z perspektywy prawa nie ma żadnego znaczenia, czy dana symulacja została wykonana przez człowieka, czy wygenerowana automatycznie. Jeżeli efekt końcowy sprawia wrażenie, że dana osoba brała udział w projekcie, wyraziła zgodę lub użyczyła swojego wizerunku bądź głosu, ryzyko naruszenia jest takie samo. Prawo chroni osobę, a nie metodę, którą osiągnięto dany rezultat.
Na przykładach historycznych Palak pokazywał, że spory dotyczące naśladowania głosu czy stylu wypowiedzi istniały na długo przed erą AI. Dzisiejsze narzędzia jedynie radykalnie obniżyły próg techniczny, dzięki czemu takie symulacje stały się masowe i łatwo dostępne. To jednak nie zmienia faktu, że osoby rozpoznawalne mogą skutecznie dochodzić swoich roszczeń, jeżeli ich cechy zostały wykorzystane bez zgody.
Szczególnie problematyczne są sytuacje komercyjne – reklamy, kampanie promocyjne czy materiały marketingowe. W takich przypadkach łatwo postawić zarzut sugerowania nieistniejącej współpracy lub aprobaty, co znacząco zwiększa ekspozycję prawną. Wniosek z tej części prelekcji był jednoznaczny: ostrożność przy inspirowaniu się celebrytami powinna być znacznie większa niż przy motywach anonimowych, niezależnie od tego, czy finalny efekt stworzył człowiek, czy algorytm.
Przykłady sporów sądowych jako sygnał ryzyka
Uzupełniając wątek ryzyk związanych z danymi treningowymi, Tomasz Palak odniósł się do głośnych sporów sądowych dotyczących AI, które regularnie pojawiają się w mediach. Zaznaczył jednak wyraźnie, że ich znaczenie dla codziennej praktyki bywa często przeceniane – nie dlatego, że są nieistotne, ale dlatego, że pełnią głównie funkcję ostrzegawczą, a nie dostarczają gotowych odpowiedzi.
Prelegent podkreślał, że medialne procesy – zwłaszcza te dotyczące trenowania modeli na cudzych treściach – rzadko przekładają się wprost na realne ryzyko po stronie użytkowników narzędzi AI. Nawet jeżeli konkretna sprawa zakończy się przełomowym wyrokiem, nie oznacza to automatycznie, że codzienne korzystanie z generatywnych modeli stanie się nagle nielegalne lub drastycznie ograniczone. Historia prawa nowych technologii pokazuje raczej, że narzędzia się zmieniają, a praktyka znajduje obejścia i alternatywy.
Palak zwracał uwagę, że z perspektywy twórców i marketerów znacznie większe znaczenie mają działania, na które mają oni realny wpływ – przede wszystkim materiały wkładane do AI oraz sposób wykorzystania efektu końcowego. To właśnie te elementy mogą stać się podstawą odpowiedzialności, niezależnie od tego, jak zakończy się spór pomiędzy dużymi podmiotami a dostawcami modeli.
W tym sensie procesy sądowe dotyczące AI warto traktować jako sygnał ostrzegawczy, pokazujący kierunek myślenia sądów i regulatorów, a nie jako bezpośrednią instrukcję działania. Dla praktyków ważniejsze od śledzenia nagłówków jest świadome zarządzanie ryzykiem tam, gdzie rzeczywiście mogą pojawić się konsekwencje prawne.
Utwór vs. wytwór – status prawny treści generowanych przez AI
W kolejnej części prelekcji Tomasz Palak przeszedł do fundamentalnego pytania o status prawny treści generowanych przez AI. Punktem wyjścia było rozróżnienie pomiędzy utworem a tym, co prelegent konsekwentnie określał jako wytwór. To rozróżnienie nie jest semantyczne, lecz ma bezpośrednie konsekwencje prawnoautorskie.
Palak przypomniał klasyczną definicję utworu jako przejawu działalności twórczej o indywidualnym charakterze. Następnie zestawił ją z typowym efektem pracy AI, powstającym w wyniku jednego polecenia, bez istotnych decyzji twórczych po stronie użytkownika. W takich przypadkach – jak podkreślał – nie mamy do czynienia z utworem, lecz z rezultatem technicznym, który co do zasady nie korzysta z ochrony prawa autorskiego.
Prelegent zwracał uwagę, że brak ochrony nie jest wyjątkiem ani luką w systemie, lecz logiczną konsekwencją obowiązujących przepisów. Jeżeli efekt nie spełnia kryterium twórczości i indywidualności, nie powstają do niego prawa autorskie – niezależnie od tego, jak atrakcyjny czy użyteczny jest rezultat. Stąd świadome użycie terminu wytwór, który lepiej oddaje charakter takich treści niż intuicyjnie używane słowo utwór.
Istotnym elementem tej części było także wskazanie praktycznych ryzyk, jakie wynikają z braku ochrony. Po pierwsze, użytkownik AI może nie mieć żadnych narzędzi prawnych, by przeciwdziałać kopiowaniu wygenerowanej treści przez osoby trzecie. Po drugie, może dojść do kolizji z zapisami umownymi – np. gdy wykonawca zobowiązuje się do dostarczenia utworu, a w praktyce przekazuje materiał, który nie spełnia kryteriów ochrony prawnoautorskiej. W takim scenariuszu problemem nie jest samo AI, lecz niespełnienie obiecanego standardu prawnego rezultatu.
AI jako narzędzie – kiedy możliwy jest wyjątek od braku ochrony
Po wskazaniu, że treści generowane przez AI co do zasady nie są utworami, Tomasz Palak wyraźnie zaznaczył, że nie jest to reguła absolutna. Istnieje bowiem istotny wyjątek: sytuacja, w której AI pełni rolę narzędzia, a nie podmiotu faktycznie decydującego o kształcie rezultatu.
Prelegent podkreślał, że kluczowe znaczenie ma tu wkład twórczy człowieka, rozumiany nie deklaratywnie, lecz bardzo konkretnie. Chodzi o scenariusze, w których użytkownik podejmuje rzeczywiste decyzje twórcze: dobiera parametry, wielokrotnie iteruje, selekcjonuje warianty, poprawia, odrzuca i świadomie zmierza do określonego efektu. Im bardziej proces przypomina pracę koncepcyjną, a nie jednorazowe naciśnięcie enter, tym większa szansa, że końcowy rezultat może zostać uznany za utwór.
Palak zwracał uwagę, że granica ta bywa niższa, niż intuicyjnie zakłada wielu użytkowników. Prawo autorskie chroni bowiem także takie formy twórczości, które na pierwszy rzut oka wydają się mało artystyczne – o ile można wykazać indywidualny i twórczy charakter procesu. W tym sensie AI może zostać porównane do klasycznego narzędzia: nie młot tworzy dzieło, lecz osoba, która świadomie się nim posługuje.
Istotnym elementem tej części wystąpienia była również kwestia dowodzenia procesu twórczego. Prelegent zaznaczał, że w razie sporu znaczenie może mieć możliwość wykazania, iż efekt nie powstał automatycznie, lecz był wynikiem szeregu decyzji i działań po stronie człowieka. Dokumentowanie iteracji, wariantów czy czasu poświęconego na pracę z AI może w praktyce przesądzić o tym, czy dany rezultat zostanie uznany za chroniony utwór, czy jedynie techniczny wytwór.
Konsekwencje braku ochrony prawnoautorskiej treści z AI
Rozwijając wątek statusu prawnego treści generowanych przez AI, Tomasz Palak zwrócił uwagę na praktyczne skutki sytuacji, w której dany materiał nie jest chroniony prawem autorskim. Brak ochrony nie jest jedynie teoretycznym problemem – może realnie wpłynąć na sposób wykorzystania takich treści w biznesie i marketingu.
Pierwszą konsekwencją jest pełna podatność na kopiowanie. Jeżeli wygenerowany materiał nie stanowi utworu w rozumieniu prawa autorskiego, jego autor nie dysponuje instrumentami, które pozwalałyby skutecznie zakazać jego dalszego używania przez osoby trzecie. W praktyce oznacza to, że treść może zostać powielona, zmodyfikowana lub wykorzystana przez konkurencję bez ryzyka naruszenia praw autorskich.
Drugim, równie istotnym aspektem, są rozbieżności pomiędzy rzeczywistością prawną a zapisami umownymi. Prelegent wskazywał, że w wielu kontraktach – zwłaszcza w obszarze usług kreatywnych – pojawia się zobowiązanie do przeniesienia praw autorskich do wytworzonego materiału. Jeżeli jednak efekt pracy z AI nie jest w ogóle utworem, prawa te nie mogą zostać przeniesione, bo… po prostu nie istnieją. Może to prowadzić do sporów, w których problemem nie będzie jakość treści, lecz niespełnienie formalnych warunków umowy.
Wniosek z tej części wystąpienia był jasny: korzystanie z AI wymaga nie tylko świadomości technologicznej, ale także spójności pomiędzy sposobem tworzenia treści a deklaracjami składanymi wobec klientów czy partnerów. W przeciwnym razie brak ochrony prawnoautorskiej może stać się źródłem nieoczekiwanych i trudnych do obrony roszczeń.
Obróbka cudzych treści w AI a pierwotne prawa autorskie
Rozpoczynając kolejny blok tematyczny, Tomasz Palak mocno zaakcentował, że użycie cudzych materiałów jako danych wejściowych do AI nie powoduje wyczyszczenia praw autorskich. Wręcz przeciwnie – pierwotne prawa do materiału źródłowego pozostają w mocy, niezależnie od tego, jak bardzo zmieni się jego forma po przejściu przez narzędzie generatywne.
Prelegent podkreślał, że częstym błędem jest przekonanie, iż skoro efekt końcowy został wygenerowany, to wcześniejsze ograniczenia prawne przestają mieć znaczenie. Tymczasem z punktu widzenia prawa kluczowe jest to, co zostało włożone do AI, a nie tylko to, co z niego wyszło. Jeżeli materiał wejściowy był chronionym utworem, jego obróbka – nawet bardzo zaawansowana – nie powoduje automatycznego wygaśnięcia praw przysługujących pierwotnemu twórcy.
Palak zwracał uwagę, że w takich sytuacjach odpowiedzialność może pojawić się niezależnie od tego, czy efekt końcowy zostanie uznany za nowy utwór, czy jedynie za wytwór techniczny. Prawa do oryginału nie znikają, a ich naruszenie może polegać już na samym fakcie nieuprawnionego wykorzystania materiału źródłowego w procesie obróbki.
W praktyce oznacza to, że korzystając z AI, znacznie większą uwagę należy poświęcić legalności inputów niż samej estetyce czy oryginalności outputu. Ryzyko prawne często nie leży w tym, że efekt przypomina czyjś styl, lecz w tym, że do systemu trafił materiał, do którego użytkownik nie posiadał odpowiednich praw.
Ryzyko ukryte w inputach, a nie w stylu
W dalszej części tego punktu Tomasz Palak zwrócił uwagę na częsty błąd popełniany przez użytkowników AI, polegający na koncentrowaniu się na samym stylu, zamiast na faktycznym źródle danych wejściowych. Prelegent podkreślał, że pytania w rodzaju czy mogę generować w stylu X? bardzo często omijają realny problem prawny.
Z perspektywy prawa autorskiego styl jako taki nie podlega ochronie, natomiast chronione są konkretne utwory. Ryzyko pojawia się więc nie wtedy, gdy model naśladuje klimat czy estetykę, lecz wtedy, gdy do systemu trafiają konkretne, cudze materiały – zdjęcia, teksty, grafiki – do których użytkownik nie posiada praw. To właśnie te materiały stanowią potencjalne źródło naruszeń, niezależnie od tego, jak bardzo zmieni się efekt końcowy.
Palak zaznaczał, że skupienie się wyłącznie na deklaratywnym unikaniu stylu może dawać fałszywe poczucie bezpieczeństwa. W praktyce bowiem problem prawny bardzo często tkwi nie w tym, co AI wygenerowało, lecz w tym, co zostało mu przekazane jako punkt wyjścia. Dlatego oceniając ryzyko, warto w pierwszej kolejności analizować legalność inputów, a dopiero w drugiej – podobieństwo estetyczne rezultatów.
Znaczenie twórczych wyborów i możliwość dowodzenia wkładu twórczego
Przechodząc do zagadnienia wkładu twórczego, Tomasz Palak podkreślił, że ochrona prawna w kontekście AI nie wynika z samego faktu użycia narzędzia, lecz z realnych, możliwych do wykazania decyzji podejmowanych przez człowieka. Kluczowe znaczenie mają tu twórcze wybory, a nie deklaracje intencji.
Prelegent wskazywał, że o wkładzie twórczym można mówić dopiero wtedy, gdy użytkownik faktycznie kontroluje proces: dobiera parametry, modyfikuje polecenia, tworzy wiele wariantów, odrzuca część rezultatów i świadomie kieruje pracą AI w określoną stronę. Taki proces – wieloetapowy i iteracyjny – może zostać uznany za działalność twórczą, nawet jeśli finalnie narzędzie generatywne odegrało istotną rolę techniczną.
Istotnym elementem tej części wystąpienia było zwrócenie uwagi na znaczenie dowodowe samego procesu pracy. Palak zaznaczał, że w razie sporu nie wystarczy stwierdzić, że AI było tylko narzędziem. Konieczne może być wykazanie, że użytkownik rzeczywiście podejmował twórcze decyzje – np. poprzez historię iteracji, zapis promptów, wariantów czy czasu poświęconego na dopracowanie efektu. To właśnie możliwość udokumentowania tych działań może przesądzić o uznaniu rezultatu za utwór.
Wniosek z tej części był jednoznaczny: im więcej świadomych decyzji i im większa kontrola nad procesem, tym większa szansa na ochronę prawną efektu końcowego. AI może być narzędziem porównywalnym do klasycznych środków twórczych, ale tylko wtedy, gdy faktycznie pozostaje podporządkowane twórczym wyborom człowieka.
Prompt jako potencjalny przedmiot ochrony
W dalszej części Tomasz Palak zwrócił uwagę na aspekt, który bywa dla uczestników zaskakujący: łatwiej jest bronić praw do promptu niż do efektu wygenerowanego przez AI. Wynika to z faktu, że prompt – w przeciwieństwie do wielu automatycznych outputów – może sam w sobie spełniać kryteria utworu.
Prelegent wskazywał, że rozbudowany prompt, będący przemyślanym zestawem poleceń, ograniczeń i zależności, może stanowić spójną całość znaczeniową, a nie jedynie techniczne hasło. W takim ujęciu prompt przestaje być prostą instrukcją, a zaczyna przypominać formę twórczego wyrażenia – podobnie jak tekst, opis koncepcji czy specyfikacja kreatywna.
Istotne było również podkreślenie kontrastu: podczas gdy efekt wygenerowany po jednym kliknięciu często nie spełnia kryteriów twórczości indywidualnej, sam proces formułowania promptu może zawierać znacznie więcej elementów decyzyjnych i autorskich. W praktyce oznacza to, że ochrona prawna może przesunąć się z rezultatu na warstwę sterującą procesem, co ma duże znaczenie przy pracy zespołowej lub komercjalizacji rozwiązań opartych o AI.
Własność promptów – umowy i brak automatycznej wyłączności
Rozwijając temat promptów, Tomasz Palak przeszedł do kwestii ich własności oraz obrotu prawnego, zwracając uwagę na kilka często pomijanych ryzyk. Podkreślał, że nawet jeżeli prompt potencjalnie spełnia kryteria utworu, nie oznacza to automatycznie, że osoba, która go używa, ma do niego wyłączne prawa.
Szczególną uwagę prelegent poświęcił relacjom pracowniczym i współpracy B2B. W przypadku umowy o pracę zastosowanie mogą mieć standardowe mechanizmy przejścia praw autorskich na pracodawcę. Oznacza to, że prompty tworzone przy okazji codziennej pracy – nawet jeśli są efektem kreatywnego namysłu – mogą należeć do firmy, a nie do konkretnego pracownika. Dla wielu uczestników była to istotna zmiana perspektywy, zwłaszcza w kontekście budowania własnych bibliotek promptów.
Palak zaznaczał również, że brak wyraźnych zapisów umownych nie daje automatycznej wyłączności. Jeżeli ktoś udostępnia prompty w ramach kursu, szkolenia czy społeczności, to co do zasady zezwala na ich używanie – ale niekoniecznie przenosi prawa w sposób, który pozwala innym twierdzić, że są one tylko ich. Jeżeli oczekiwana jest wyłączność lub pełne przejęcie praw, musi to wynikać wprost z umowy i być odpowiednio sformalizowane.
W praktyce oznacza to, że prompty – mimo rosnącej wartości biznesowej – podlegają tym samym zasadom obrotu prawami autorskimi co inne treści. Bez jednoznacznych ustaleń łatwo o błędne założenie, że skoro coś zostało stworzone samodzielnie lub kupione, to automatycznie jest wolne od ograniczeń. W realiach pracy z AI taka nieostrożność może szybko przełożyć się na konflikty lub utratę kontroli nad własnymi rozwiązaniami.
Obchodzenie zabezpieczeń technicznych i wzrost odpowiedzialności
W kolejnym punkcie Tomasz Palak omówił ryzyka związane z obchodzeniem technicznych zabezpieczeń narzędzi AI, podkreślając, że jest to jeden z najszybszych sposobów na znaczące zwiększenie odpowiedzialności prawnej użytkownika. W jego ocenie moment świadomego obejścia ograniczeń narzuconych przez system stanowi wyraźną granicę pomiędzy nieumyślnym błędem a działaniem celowym.
Prelegent zwracał uwagę, że zabezpieczenia – takie jak blokady określonych poleceń, filtrowanie nazwisk, stylów czy kategorii treści – pełnią również funkcję sygnalizacyjną. Informują użytkownika, że dany obszar jest potencjalnie problematyczny prawnie. Jeżeli mimo to użytkownik świadomie szuka obejść, stosuje synonimy, ekwiwalenty lub inne techniki pozwalające uzyskać zakazany efekt, traci argument braku wiedzy lub nieświadomości ryzyka.
Palak podkreślał, że z perspektywy ewentualnego sporu takie działanie może zostać ocenione znacznie surowiej niż wygenerowanie problematycznej treści w wyniku błędu systemu. Obchodzenie zabezpieczeń sugeruje bowiem intencję i świadomość konsekwencji, co wpływa zarówno na ocenę odpowiedzialności, jak i na sposób postrzegania użytkownika przez sąd. W praktyce oznacza to, że sprytne techniczne obejścia mogą okazać się najdroższym możliwym skrótem w pracy z AI.
Świadome działanie użytkownika a błąd systemu
Uzupełniając wątek obchodzenia zabezpieczeń, Tomasz Palak zwrócił uwagę na znaczenie intencji użytkownika przy ocenie odpowiedzialności prawnej. Kluczowe jest rozróżnienie pomiędzy sytuacją, w której problematyczny rezultat pojawia się w wyniku błędu lub nieprzewidywalnego działania systemu, a przypadkiem, gdy użytkownik działa w sposób świadomy i celowy.
Prelegent podkreślał, że w praktyce prawnej ta różnica ma realne znaczenie. Jeżeli użytkownik korzysta z narzędzia w standardowy sposób, a kontrowersyjny efekt jest wynikiem halucynacji modelu lub niedoskonałości algorytmu, łatwiej argumentować brak zawinienia. Inaczej oceniane są jednak sytuacje, w których użytkownik wie, że dany obszar jest ryzykowny, a mimo to podejmuje działania zmierzające do uzyskania zakazanego lub problematycznego rezultatu.
Palak zaznaczał, że sąd – podobnie jak każdy odbiorca takiej sytuacji – patrzy nie tylko na sam efekt, ale również na ciąg zdarzeń, który do niego doprowadził. Świadome testowanie granic systemu, ignorowanie komunikatów ostrzegawczych czy powtarzalne próby uzyskania określonego wyniku mogą zostać odczytane jako działanie z pełną świadomością ryzyka. To z kolei znacząco osłabia linię obrony opartą na błędzie narzędzia, nawet jeśli technicznie to AI wygenerowało finalny rezultat.
Trudność wykazania realnej szkody
Przechodząc do kwestii odpowiedzialności za naruszenia, Tomasz Palak zwrócił uwagę na praktyczne problemy z dochodzeniem roszczeń w sporach dotyczących treści tworzonych lub przetwarzanych z użyciem AI. Jednym z kluczowych wyzwań jest wykazanie realnej szkody, co w praktyce bywa znacznie trudniejsze, niż mogłoby się wydawać.
Prelegent podkreślał, że samo naruszenie prawa autorskiego nie zawsze automatycznie przekłada się na łatwe do udowodnienia straty finansowe. W wielu przypadkach mamy do czynienia z tekstami, grafikami czy innymi formami contentu, gdzie bezpośredni uszczerbek ekonomiczny jest trudny do jednoznacznego wykazania. Konieczność udowodnienia, że konkretne działanie spowodowało wymierną stratę, stanowi realną barierę procesową.
Z perspektywy praktyki oznacza to, że nawet jeżeli doszło do naruszenia, spór nie zawsze kończy się wysokimi roszczeniami finansowymi. Właśnie dlatego – jak zaznaczał Palak – wiele potencjalnych konfliktów nie trafia na wokandę lub kończy się na etapie przedsądowym. Trudność dowodowa nie eliminuje ryzyka całkowicie, ale istotnie wpływa na skalę i sposób egzekwowania odpowiedzialności.
Alternatywne sposoby dochodzenia roszczeń – odniesienie do stawek rynkowych
W dalszej części Tomasz Palak wskazał, że trudność w wykazaniu realnej szkody nie oznacza braku jakichkolwiek narzędzi dochodzenia roszczeń. Prawo autorskie przewiduje bowiem alternatywną ścieżkę, która w praktyce bywa znacznie łatwiejsza do zastosowania niż klasyczne wykazywanie poniesionej straty.
Prelegent zwrócił uwagę na możliwość odwołania się do stawek rynkowych, czyli wynagrodzenia, jakie uprawniony standardowo otrzymuje za legalne wykorzystanie danego typu treści. W takim modelu nie trzeba udowadniać, że doszło do konkretnego uszczerbku finansowego – wystarczające może być wykazanie, że cudzy utwór został wykorzystany bez zgody, a autor posiada ustaloną praktykę wynagradzania za tego rodzaju użycie.
Palak podkreślał, że ta konstrukcja ma szczególne znaczenie w branżach kreatywnych, takich jak fotografia, grafika czy profesjonalny copywriting, gdzie funkcjonują względnie czytelne cenniki i modele rozliczeń. W takich przypadkach spór nie toczy się o abstrakcyjną szkodę, lecz o to, ile kosztowałoby legalne nabycie prawa do wykorzystania materiału.
Jednocześnie zaznaczał, że mechanizm ten nie zawsze prowadzi do spektakularnych kwot – jego siła leży raczej w uproszczeniu drogi dochodzenia roszczeń niż w automatycznym windowaniu odpowiedzialności finansowej. Dla użytkowników AI oznacza to jednak, że nawet przy braku oczywistej szkody ekonomicznej, naruszenie cudzych praw może wiązać się z realnymi kosztami, opartymi na rynkowych standardach wynagrodzenia.
Praktyczne skutki sporów – finansowe i wizerunkowe
W tym miejscu Tomasz Palak jedynie sygnalizował praktyczne konsekwencje sporów prawnych związanych z AI, nie wchodząc w szczegółowe analizy. Zwrócił uwagę, że nawet jeśli ryzyko wysokich odszkodowań bywa ograniczone, sam spór może generować koszty finansowe, czasowe i organizacyjne, które dla wielu firm są istotnym obciążeniem.
Równie ważny – a często bardziej dotkliwy – bywa wymiar wizerunkowy. Konflikty dotyczące nieuprawnionego wykorzystania treści, wizerunku czy stylu mogą negatywnie wpływać na postrzeganie marki, zwłaszcza w branżach opartych na zaufaniu i reputacji. Dlatego nawet przy relatywnie niskim ryzyku stricte finansowym, prelegent sugerował traktować takie sytuacje jako element szerszego zarządzania ryzykiem.
Obowiązek oznaczania treści tworzonych z użyciem AI – perspektywa AI Act
Przechodząc do regulacji przyszłych, Tomasz Palak odniósł się do AI Act i wyraźnie oddzielił medialne narracje o rewolucji od realnych obowiązków, z którymi użytkownicy AI będą musieli się zmierzyć. W jego ocenie najważniejszym i najbardziej praktycznym skutkiem nowych regulacji jest obowiązek oznaczania treści tworzonych z użyciem AI, który zacznie obowiązywać od sierpnia.
Prelegent podkreślał, że nie chodzi tu o zakaz korzystania z narzędzi generatywnych ani o radykalną przebudowę prawa autorskiego, lecz o transparentność wobec odbiorcy. Oznaczanie ma informować, że dany materiał powstał z użyciem AI – niezależnie od tego, czy mówimy o grafice, tekście czy innym rodzaju contentu. W praktyce jest to wymóg formalny, który ma ograniczać wprowadzanie odbiorców w błąd, a nie rozstrzygać kwestie autorstwa czy praw do treści.
Palak zaznaczał, że dla wielu twórców i marketerów nie będzie to zupełnie nowa praktyka. W części kanałów – zwłaszcza w mediach społecznościowych – podobne oznaczenia funkcjonują już dziś, choć często w sposób niejednolity i dobrowolny. AI Act wprowadza tu obowiązek systemowy, który będzie trzeba uwzględnić w procesach publikacji treści, również po stronie firm i agencji.
Istotne było również to, że prelegent nie traktował tego wymogu jako szczególnie dotkliwego. W jego ocenie jest to raczej kolejny element formalny, który należy poprawnie wdrożyć, niż źródło istotnych ograniczeń kreatywnych. Kluczowe ryzyko nie polega na samym oznaczeniu, lecz na jego braku – zwłaszcza w sytuacjach, w których odbiorca mógłby zostać wprowadzony w błąd co do sposobu powstania treści.
Ograniczony wpływ AI Act na bieżącą praktykę twórczą
W dalszej części Tomasz Palak tonował oczekiwania wobec AI Act, podkreślając, że nowe regulacje nie wprowadzają rewolucji w prawie autorskim ani w codziennej pracy twórców, marketerów czy zespołów SEO. Wbrew obawom pojawiającym się w dyskusjach branżowych, AI Act nie rozstrzyga na nowo kwestii autorstwa ani nie tworzy odrębnego reżimu ochrony dla treści generowanych przez AI.
Prelegent zaznaczał, że większość problemów omawianych w trakcie prelekcji – takich jak podobieństwo, inspiracja, wkład twórczy czy prawa do materiałów wejściowych – już dziś podlega ocenie na gruncie obowiązujących przepisów. AI Act nie zmienia tych zasad, a jedynie dokłada warstwę regulacyjną związaną z transparentnością i odpowiedzialnym użyciem technologii.
W praktyce oznacza to, że nie ma sensu wstrzymywać się z decyzjami czy strategiami do momentu pełnego wdrożenia nowych przepisów. Jak podkreślał Palak, ryzyka prawne związane z AI istnieją już teraz i powinny być analizowane w oparciu o aktualne regulacje, a nie przyszłe akty prawne. AI Act porządkuje pewne obszary, ale nie stanowi punktu zwrotnego w rozumieniu prawa autorskiego ani kreatywnego wykorzystania AI.
Na marginesie omawiania AI Act Tomasz Palak zaznaczył, że wiele kwestii praktycznych – w szczególności dotyczących sposobu poprawnego oznaczania treści tworzonych z użyciem AI – wymaga jeszcze doprecyzowania. Podkreślał, że sam obowiązek jest jasny, natomiast szczegóły jego realizacji będą stopniowo porządkowane i wyjaśniane w praktyce.
Możliwość braku ochrony prawnej treści generowanych przez AI
Tomasz Palak ponownie zaakcentował jedno z najbardziej fundamentalnych ryzyk pracy z AI: możliwość, że wygenerowana treść w ogóle nie będzie podlegać ochronie prawnoautorskiej. Jak podkreślał, dla wielu osób jest to wciąż wniosek nieintuicyjny, zwłaszcza gdy efekt końcowy wygląda profesjonalnie i spełnia oczekiwania biznesowe.
Prelegent przypominał, że brak ochrony nie wynika z jakości materiału, lecz z braku spełnienia przesłanek twórczości i indywidualności. Jeżeli AI wytwarza treść w sposób automatyczny, a wkład człowieka ogranicza się do jednego, prostego polecenia, rezultat pozostaje wytworem technicznym, a nie utworem w rozumieniu prawa. W takiej sytuacji użytkownik nie nabywa monopolu prawnego, który normalnie towarzyszy twórczości chronionej.
Palak zwracał uwagę, że to ryzyko ma bardzo praktyczny wymiar. Treści pozbawione ochrony mogą być swobodnie kopiowane, adaptowane i wykorzystywane przez innych, bez możliwości skutecznej reakcji prawnej. Co więcej, brak ochrony może ujawnić się dopiero w momencie konfliktu – np. gdy klient oczekuje przeniesienia praw autorskich albo gdy pojawia się spór o wyłączność wykorzystania materiału.
Wniosek, który wybrzmiewał w tej części szczególnie mocno, był prosty: korzystanie z AI nie gwarantuje powstania praw autorskich, a błędne założenie, że skoro stworzyłem, to jest moje, może prowadzić do poważnych konsekwencji prawnych i biznesowych.
Ryzyko wynikające z materiałów wejściowych
Drugim kluczowym ryzykiem, które Tomasz Palak wyraźnie wyeksponował w podsumowaniu, jest odpowiedzialność wynikająca z użytych materiałów wejściowych, a nie z samego faktu generowania treści przez AI. Prelegent podkreślał, że w praktyce to właśnie inputy są najczęstszym i najbardziej niedocenianym źródłem problemów prawnych.
Palak zwracał uwagę, że nawet jeśli efekt końcowy wydaje się bezpieczny, przekształcony lub wystarczająco inny, pierwotne prawa do materiałów źródłowych nie znikają. Włożenie do AI cudzego tekstu, grafiki, zdjęcia czy nagrania – bez odpowiednich uprawnień – może samo w sobie stanowić naruszenie, niezależnie od tego, jak bardzo zmieni się rezultat po obróbce.
Istotne było również podkreślenie, że użytkownicy często skupiają się na analizie outputu: podobieństwie, stylu czy rozpoznawalności efektu. Tymczasem z punktu widzenia prawa znacznie ważniejsze jest pytanie, czy użytkownik miał prawo do tego, co przekazał narzędziu na wejściu. To przesunięcie perspektywy – z efektu na źródło – było jednym z najmocniejszych akcentów całej prelekcji.
W praktyce oznacza to, że nawet ostrożne i kreatywne korzystanie z AI nie eliminuje ryzyka, jeżeli proces zaczyna się od materiałów, do których użytkownik nie posiada pełnych praw. Jak podkreślał prelegent, to właśnie ten obszar najczęściej staje się punktem zaczepienia w ewentualnych sporach.
Znaczenie dokumentowania wkładu twórczego
W dalszej części podsumowania Tomasz Palak zwrócił uwagę na praktyczne znaczenie dokumentowania procesu pracy z AI, zwłaszcza tam, gdzie użytkownik liczy na ochronę prawną efektu końcowego. Jak podkreślał wcześniej, o istnieniu praw autorskich decyduje nie deklaracja, lecz możliwość wykazania twórczych i indywidualnych wyborów – a to wprost przekłada się na potrzebę dowodów.
Prelegent zaznaczał, że w razie sporu kluczowe może być pokazanie, iż praca z AI miała charakter iteracyjny i decyzyjny: wybór parametrów, modyfikowanie promptów, selekcja wariantów czy czas poświęcony na dopracowanie rezultatu. Bez takiej dokumentacji nawet realny wkład twórczy może okazać się trudny do obrony, bo z zewnątrz efekt będzie wyglądał jak prosty, automatyczny wytwór.
W tym sensie dokumentowanie pracy z AI pełni funkcję zabezpieczającą – nie przesądza automatycznie o ochronie, ale znacząco zwiększa szanse na jej wykazanie, jeżeli pojawi się konflikt prawny lub wątpliwości po stronie klienta czy partnera biznesowego.
Rekomendacje ostrożnościowe – sygnałowe wnioski końcowe
Na sam koniec Tomasz Palak zarysował hasłowe rekomendacje ostrożnościowe, bez ich szczegółowego rozwijania. Miały one charakter sygnałów ostrzegawczych, a nie checklisty czy instrukcji postępowania.
Prelegent wskazał m.in. na potrzebę większej uważności przy pracy z AI tam, gdzie w grę wchodzą cudze materiały, osoby rozpoznawalne lub zobowiązania umowne. Podkreślał również znaczenie świadomego korzystania z narzędzi – bez testowania granic zabezpieczeń i bez automatycznego założenia, że technologia rozwiązuje problemy prawne.
Te końcowe uwagi nie miały charakteru normatywnego, lecz pełniły funkcję ramy ostrożnościowej: przypomnienia, że AI nie znosi odpowiedzialności, a wiele ryzyk pozostaje takich samych jak przed jej upowszechnieniem – jedynie łatwiejszych do uruchomienia w praktyce.
Łukasz Kacprzak – Rok z GEO okiem produktowca
Prelegent już na początku prelekcji jasno zarysował ramę interpretacyjną całego wystąpienia: rozwój AI i modeli językowych nie oznacza końca SEO, lecz kolejny etap jego ewolucji. Zwrócił uwagę, że narracja o śmierci SEO pojawia się cyklicznie przy każdej większej zmianie technologicznej, natomiast w praktyce mamy do czynienia z dostosowywaniem narzędzi, procesów i punktów ciężkości, a nie z zanikiem samej dyscypliny. W tym ujęciu GEO i praca pod LLM-y są naturalnym rozszerzeniem dotychczasowych działań, a nie ich zaprzeczeniem.
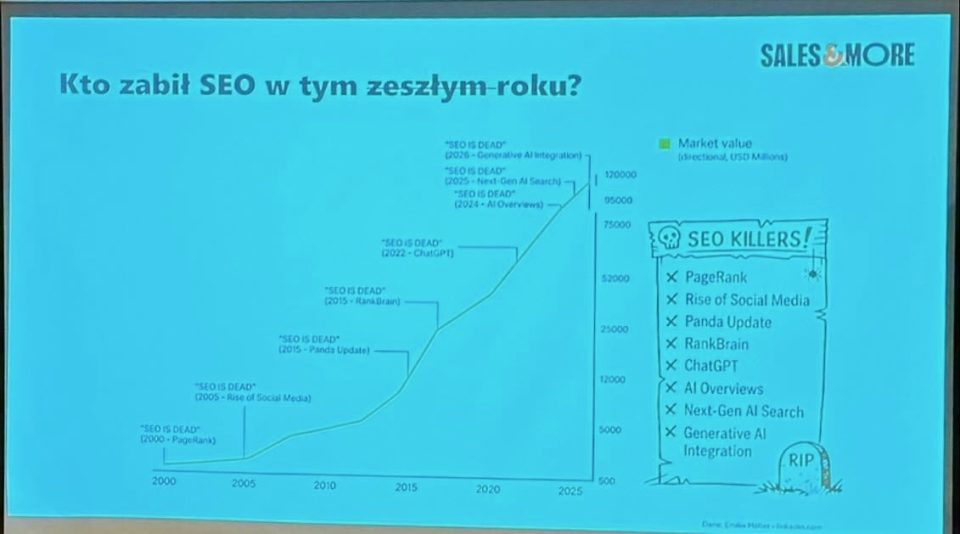
W tle tej tezy pojawił się istotny kontekst organizacyjny: różnica perspektyw między zespołem SEO a podejściem produktowym. Łukasz Kacprzak zwrócił uwagę, że decyzje wdrożeniowe często wynikają nie z akademickiego przekonania o skuteczności danego rozwiązania, lecz z realnych potrzeb biznesowych, oczekiwań klientów i presji rynkowej. To napięcie – pomiędzy tym, co idealne z punktu widzenia SEO, a tym, co konieczne z punktu widzenia produktu i sprzedaży – stanowiło punkt wyjścia do dalszych przykładów i case’ów omawianych w kolejnych częściach prelekcji.
Wdrożenia techniczne pod LLM / AI
LLMs.txt jako odpowiedź na potrzeby rynku, nie akt wiary w skuteczność
Jednym z pierwszych omawianych wdrożeń był plik LLMs.txt, który – jak podkreślał prelegent – pojawił się nie dlatego, że zespół był przekonany o jego realnym wpływie, lecz dlatego, że… klienci zaczęli o niego pytać. W ofertach i audytach przygotowywanych przez podmioty trzecie coraz częściej pojawiała się informacja o jego braku jako niedociągnięciu, co z perspektywy produktowej stawiało zespół pod presją reakcji.
Łukasz Kacprzak zwrócił uwagę na wyraźny podział w branży: część specjalistów kwestionuje sens istnienia LLMs.txt, wskazując na brak dowodów jego wykorzystania w praktyce, szczególnie na rynku polskim. Mimo to decyzja o wdrożeniu zapadła, ponieważ koszt braku pliku – wizerunkowy i sprzedażowy – okazywał się wyższy niż koszt samego wdrożenia. W tym kontekście padła istotna obserwacja: z punktu widzenia produktu często wygrywa spełnienie oczekiwań rynku, nawet jeśli nie idzie za tym twarda walidacja skuteczności.
Koszt i skalowalność w dużych serwisach
Przy większych projektach, zwłaszcza e-commerce z dziesiątkami tysięcy podstron, ręczne tworzenie i utrzymanie LLMs.txt byłoby nieefektywne. Dlatego wdrożenie zostało potraktowane jako problem skalowalny technologicznie, a nie redakcyjnie – z naciskiem na automatyzację i minimalizację kosztu jednostkowego.
Automatyzacja generowania LLMs.txt
Technicznie proces oparto o dane z crawlów oraz generowanie treści w oparciu o Markdown i pliki CSV. Wykorzystanie prostych skryptów pozwoliło automatycznie tworzyć pliki LLMs.txt zarówno dla standardowych podstron HTML, jak i dla zasobów PDF. Była to raczej wzmianka techniczna niż pełny instruktaż, ale dobrze ilustrowała podejście: szybkie wdrożenie, możliwe do powielenia na wielu projektach.
Treści w Markdownie i generowanie warunkowe
Kolejnym eksperymentem było udostępnianie treści w formacie Markdown. Testy nie dały jednoznacznej odpowiedzi co do wpływu na widoczność, jednak zespół zauważył pojawienie się nowych bytów i podstaw, które wcześniej nie były rejestrowane. Aby ograniczyć potencjalne skutki uboczne, treści w Markdownie generowane były warunkowo – tylko dla określonych user agentów – co pozwalało zachować kontrolę nad ich dystrybucją.
Rozszerzenie danych strukturalnych poza logikę snippetów
W obszarze danych strukturalnych nastąpiło odejście od podejścia ograniczonego wyłącznie do tego, co Google wykorzystuje w snippetach. Zamiast selektywnego wdrażania schema.org, zespół zaczął modelować pełne zestawy danych, wychodząc z założenia, że LLM-y nie mają tych samych ograniczeń co klasyczna wyszukiwarka. Szczególnie istotne było to w projektach złożonych, np. w sektorze finansowym.
Przeredagowywanie treści pod semantykę LLM
Ostatnim elementem tej części były zmiany w redakcji treści. Nie oznaczały one rewolucji w stylu pisania, ponieważ treści już wcześniej były tworzone prostym, użytkowym językiem. Kluczowym usprawnieniem było wprowadzenie semantycznych trójek – struktur informacji łatwo przyswajalnych przez modele językowe. Całość została przedstawiona jako naturalna ewolucja istniejących praktyk, a nie zmiana filozofii contentowej.
Content i kontrola jakości treści generowanych z AI
W tej części prelekcji Łukasz Kacprzak przeszedł od technologii do odpowiedzialności redakcyjnej, wyraźnie zaznaczając, że największym ryzykiem pracy z AI nie są same modele, lecz sposób ich wykorzystania. W jego ujęciu kluczowe jest przesunięcie ciężaru z produkowania treści na realną kontrolę jakości i świadome podejmowanie decyzji o publikacji.
Podstawową zasadą, którą zespół wdrożył operacyjnie, jest ludzki proofreading każdej treści powstałej przy wsparciu AI. Nie chodzi tu wyłącznie o poprawność językową, ale o ogólną wartość materiału. Prelegent przywołał prosty filtr decyzyjny stosowany wewnętrznie: czy dany artykuł można byłoby bez wahania wysłać koledze z branży jako coś sensownego i wartego przeczytania. Jeśli odpowiedź brzmi negatywnie, treść wraca do poprawy albo w ogóle nie trafia do publikacji. W tym modelu AI pełni rolę asystenta, a nie autora końcowego, a pełna odpowiedzialność za efekt zawsze spoczywa po stronie zespołu.
Szczególne znaczenie ten proces ma w przypadku treści wrażliwych, zwłaszcza z obszarów finansowych, medycznych czy inwestycyjnych. W tych segmentach błędy merytoryczne mogą prowadzić nie tylko do utraty wiarygodności, ale również do realnych konsekwencji prawnych. Dlatego AI wykorzystywane jest tam wyłącznie pomocniczo, np. do strukturyzowania materiału czy wsparcia redakcyjnego, natomiast weryfikacja faktów i ostateczna decyzja publikacyjna pozostają po stronie ludzi. Jak podkreślał prelegent, odpowiedzialność za ewentualne skutki takich treści zawsze ponosi agencja, a nie model językowy.
Aby ograniczyć ryzyko niespójności lub naruszeń, zespół wspiera się notebookami LLM, w których gromadzone są materiały źródłowe: regulaminy, treści publiczne, planowane publikacje czy dokumenty referencyjne. Na ich podstawie weryfikowane są kolejne wersje contentu – pod kątem zgodności z bazą wiedzy, spójności przekazu oraz potencjalnych problemów formalnych. To podejście pozwala zachować porządek nawet przy większej skali produkcji treści.
Na marginesie tej części pojawił się również temat cytatów i opinii klientów. W praktyce są one przygotowywane wewnętrznie i przekazywane do akceptacji, a w niektórych przypadkach dodatkowo stylizowane tak, aby odpowiadały rzeczywistemu sposobowi wypowiedzi danej osoby. Wystąpienie jedynie sygnalizowało ten wątek, traktując go jako detal procesu redakcyjnego, a nie jego główną oś.
Off-site i sygnały zewnętrzne
W dalszej części wystąpienia prelegent przeszedł do zagadnień off-site, pokazując je jako uzupełnienie wcześniejszych działań on-site’owych i contentowych. W tym obszarze nie pojawiły się rewolucyjne techniki, raczej świadome przesunięcie akcentów i uproszczenie procesów tam, gdzie było to możliwe.
W kontekście pozyskiwania wzmianek Łukasz Kacprzak zwrócił uwagę na odejście od typowo komercyjnych narzędzi monitorujących. Zamiast rozbudowanych platform wykorzystywany jest Google Alerts, który w przypadku marek posiadających już minimalną rozpoznawalność okazuje się wystarczającym źródłem informacji. Monitoring opiera się na reagowaniu na pojawiające się wzmianki – kontaktowaniu się z autorami publikacji, proszeniu o doprecyzowanie kontekstu lub uzupełnienie informacji o marce tam, gdzie jest to zasadne. Całość ma charakter działań reaktywnych, a nie masowego link buildingu.
Drugim istotnym wątkiem były publikacje eksperckie i cytowania specjalistów. Zespół świadomie wykorzystuje obecność ekspertów jako źródło naturalnych wzmianek, traktując ich aktywność jako element kontroli obecności marki w zewnętrznych serwisach. Jeżeli pojawiają się cytowania lub odwołania do publikacji eksperckich, są one monitorowane i analizowane pod kątem kontekstu oraz spójności przekazu. W tym ujęciu off-site przestaje być wyłącznie techniką SEO, a zaczyna pełnić funkcję narzędzia porządkowania i wzmacniania wizerunku marki w ekosystemie treści.
Social media w kontekście AI
Kolejny wątek prelekcji dotyczył roli social mediów, które zostały przedstawione nie jako klasyczny kanał zasięgowy czy sprzedażowy, lecz jako istotne źródło danych dla modeli językowych. Łukasz Kacprzak zwrócił uwagę, że treści publikowane w socialach coraz częściej funkcjonują jako sygnały opisujące markę, produkt i sposób ich postrzegania, szczególnie w kontekście odpowiedzi generowanych przez LLM-y.
Szczególne znaczenie ma tu warstwa tekstowa postów, a zwłaszcza ich początkowy fragment. Prelegent podkreślał, że w praktyce użytkownik – np. na Instagramie czy Facebooku – widzi najczęściej tylko pierwsze zdania opisu i bardzo rzadko rozwija całość. To właśnie ten fragment staje się jednocześnie miejscem na zakomunikowanie kluczowych informacji o marce, produkcie czy opinii, a także elementem, który może być przetwarzany przez modele językowe. Z perspektywy GEO jest to więc obszar wymagający znacznie większej świadomości niż dotychczas.
Wystąpienie odwoływało się również do obserwacji z rynków anglojęzycznych, gdzie treści z TikToka, Instagrama czy Facebooka coraz częściej pojawiają się jako źródła wykorzystywane przez LLM-y. W tym kontekście social media przestają być wyłącznie narzędziem komunikacji z użytkownikami, a zaczynają pełnić funkcję dodatkowej warstwy informacyjnej w ekosystemie AI.
Operacyjnie zespół nie prowadzi klasycznych działań social mediowych we własnym zakresie. Zamiast tego przygotowywane są algorytmiczne opisy postów, które wspierają inne zespoły lub podmioty odpowiedzialne za publikację. To podejście ma charakter pomocniczy i nie zastępuje tradycyjnego social media marketingu, ale pozwala zadbać o spójność komunikacji i obecność kluczowych sygnałów tam, gdzie faktycznie mogą one zostać wykorzystane przez modele językowe.
Case study: lokalne SEO (Local proof)
W centralnej części prelekcji Łukasz Kacprzak zaprezentował rozbudowane case study z obszaru lokalnego SEO, które miało stanowić praktyczny dowód na to, że klasyczne działania SEO – odpowiednio połączone z GEO i pracą pod AI – nadal przynoszą wymierne efekty biznesowe. Punkt wyjścia projektu był wyjątkowo trudny: nowy klient, zerowa widoczność w wyszukiwarce oraz bardzo silna konkurencja lokalna. W samej Warszawie działało kilkaset podmiotów oferujących ten sam, ogólnodostępny produkt, a dodatkowym problemem była nazwa brandowa – skrajnie generyczna i obecna w milionach wyników wyszukiwania.
Na etapie planowania pojawiła się naturalna wątpliwość dotycząca zmiany nazwy marki. Ostatecznie jednak, ze względów biznesowych i kosztowych, zapadła decyzja o pozostaniu przy istniejącym brandzie. Kluczowe było tu nastawienie klienta, który wykazał się dużą elastycznością i gotowością do eksperymentów, pozostawiając zespołowi szeroką swobodę decyzyjną w zakresie strategii i alokacji budżetu. To umożliwiło skoncentrowanie się na działaniach, które miały realnie pociągnąć projekt do przodu.
Strategia wejścia została oparta na połączeniu brandu z frazami produktowymi. Założenie było proste: jeśli nie uda się zbić i osadzić nazwy marki w kontekście konkretnego produktu, dalsze działania marketingowe nie będą miały sensu. Dlatego pierwszym celem było zbudowanie widoczności właśnie na tych zapytaniach, które bezpośrednio przekładały się na intencję zakupową i kontakt z firmą.
Równolegle rozpoczęto intensywną budowę sygnałów lokalnych. Zespół zadbał o spójne i szerokie wystąpienie danych NAP w kluczowych źródłach: od Google Maps, przez Apple Maps i OpenStreetMap, po mniej oczywiste serwisy, takie jak Janosik. Wszędzie tam, gdzie istniała możliwość potwierdzenia istnienia biznesu w fizycznej lokalizacji, dane zostały uzupełnione lub uporządkowane. Celem było jednoznaczne zakomunikowanie algorytmom – zarówno wyszukiwarek, jak i systemów AI – że mamy do czynienia z realnie funkcjonującą firmą.
Ciekawym elementem strategii było wykorzystanie social mediów jako pierwszego kanału obecności marki. Ze względu na czasochłonny proces przebudowy strony internetowej, profile społecznościowe pojawiły się wcześniej niż sama witryna. Pozwoliło to rozpocząć budowanie rozpoznawalności, publikować treści edukacyjne i wprowadzić markę do obiegu informacyjnego jeszcze przed pełnym startem serwisu. W kontekście AI okazało się to szczególnie istotne, ponieważ to właśnie social media stały się jednym z pierwszych źródeł, z których modele mogły uczyć się istnienia nowego podmiotu.
W dalszej kolejności uruchomiono działania link buildingowe, w tym płatne publikacje w serwisach o dużej sile oddziaływania. Klient został przekonany do inwestycji w jakościowe materiały eksperckie, a przy pozytywnych efektach zaplanowano również szeroką ekspozycję w dużym portalu ogólnopolskim. Działania te miały charakter wizerunkowo-wzmacniający, a nie masowy.
Efekty SEO pojawiły się stosunkowo szybko. Widoczność rosła systematycznie, a kluczowe frazy produktowe zaczęły osiągać wysokie pozycje, w tym miejsca tuż za liderem rynku, którym była ogólnopolska sieć posiadająca placówki w wielu miastach. Równolegle przełożyło się to na wymierne efekty biznesowe: setki zapytań dotyczących głównego produktu oraz wysoka średnia wartość klienta sprawiły, że projekt zaczął się finansowo spinać. Dodatkowym wsparciem były kampanie płatne, które uzupełniały działania organiczne i przyspieszały skalowanie efektów.
Monitoring obecności w AI i LLM
Po omówieniu działań wdrożeniowych i efektów lokalnego SEO prelegent przeszedł do tematu monitorowania obecności marek w odpowiedziach generowanych przez modele językowe. Wskazał przy tym na bardzo istotny problem operacyjny: brak klasycznych, twardych danych, do których branża SEO jest przyzwyczajona w kontekście wyszukiwarek.
W praktyce do obserwacji tego obszaru wykorzystywane jest narzędzie Chartbeat, które pozwala śledzić, jak często i w jakim kontekście dana marka lub produkt pojawia się w odpowiedziach LLM-ów. Monitoring opiera się na zestawach pytań branżowych, lokalnych oraz produktowych, dzięki czemu możliwe jest porównywanie trendów w czasie i obserwowanie zmian w sposobie prezentowania marki przez modele. Jak zaznaczył Łukasz Kacprzak, takie podejście daje przede wszystkim punkt odniesienia – pozwala sprawdzić, czy widoczność rośnie, spada lub pozostaje na tym samym poziomie po wdrożeniu konkretnych działań.
Jednocześnie mocno wybrzmiało zastrzeżenie dotyczące ograniczeń tych danych. Prelegent podkreślał, że nie są to estymacje, na podstawie których można dziś rzetelnie rozliczać efekty czy budować prognozy biznesowe. Dane mają charakter poglądowy i benchmarkowy – pokazują kierunek zmian, ale nie dają odpowiedzi na pytanie, czy wynik jest dobry lub zły w absolutnym sensie. Z tego względu komunikacja z klientami opiera się na pełnej transparentności i jasno zaznaczonym zakresie interpretacji.
Na marginesie pojawiła się również krótka wzmianka o obecności w różnych modelach i interfejsach AI, takich jak Gemini czy rozwiązania typu AIO. Temat ten nie był szeroko rozwijany i został potraktowany jako dodatkowy kontekst, pokazujący jedynie, że ekosystem modeli jest zróżnicowany, a obecność w jednym z nich nie gwarantuje automatycznie widoczności w pozostałych.
Reklama i dane
W kolejnej, krótszej części prelekcji Łukasz Kacprzak odniósł się do obszaru reklamy w kontekście AI, traktując go przede wszystkim jako potencjalne źródło nowych danych, a nie jako dojrzały kanał do optymalizacji. Zwrócił uwagę, że pojawiające się formaty reklamowe w środowiskach opartych o modele językowe mogą w przyszłości dostarczać bardzo wartościowych sygnałów o intencjach użytkowników i sposobie podejmowania decyzji.
Jednocześnie mocno wybrzmiało zastrzeżenie dotyczące aktualnych ograniczeń tego obszaru. Na dziś brakuje pełnej mierzalności i jasnych modeli atrybucji, które pozwalałyby realnie oceniać wpływ reklam w AI na wyniki biznesowe. Z tego względu temat został potraktowany bardziej jako kierunek obserwacji i eksperymentów niż jako obszar gotowy do skalowania. W ujęciu prelegenta reklama w AI to raczej zapowiedź przyszłych możliwości analitycznych niż narzędzie, które można już dziś precyzyjnie rozliczać.
Kierunki dalszego rozwoju
Ostatnia część prelekcji miała charakter produktowy i była spojrzeniem w przyszłość działań SEO oraz GEO z perspektywy skalowania. Łukasz Kacprzak podkreślał, że dalszy rozwój nie może opierać się na pojedynczych, jednorazowych wdrożeniach, lecz na standaryzacji i powtarzalności procesów. Tylko w takim modelu możliwe jest realne porównywanie efektów i wyciąganie wniosków, które mają wartość nie tylko operacyjną, ale też decyzyjną. Jeśli każde działanie realizowane jest inaczej, trudno ocenić, co faktycznie zadziałało, a co było jedynie efektem ubocznym innych zmian.

W tym kontekście pojawił się wątek dalszej optymalizacji treści poradnikowych i zakupowych. Prelegent zwrócił uwagę, że coraz większe znaczenie będą miały realne przewagi produktowe, jasno komunikowane w treściach. Nie chodzi wyłącznie o poprawność merytoryczną, lecz o takie przedstawienie produktu, które odróżnia go od konkurencji i daje algorytmom – zarówno wyszukiwarek, jak i modeli językowych – jednoznaczny sygnał, dlaczego dana oferta jest inna lub lepsza.
Kolejnym kierunkiem rozwoju są własne rankingi oraz zaplecza rankingowe. Zamiast traktować je jako klasyczne źródło ruchu, prelegent wskazywał na ich potencjał w budowaniu kontrolowanego środowiska porównań i narracji rynkowej. Podobnie zaplecza branżowe i publikacje PR-owe zostały przedstawione jako naturalne rozszerzenie działań realizowanych już dziś przy dużych markach, z tą różnicą, że w tym modelu zespół zachowuje pełną kontrolę nad strukturą i treścią publikacji.
W planach rozwojowych pojawił się również mocniejszy nacisk na formaty wizualne i wideo. Obejmują one zarówno tworzenie infografik, jak i bardziej zaawansowane materiały oparte o scenariusze i nagrania. Wideo zostało określone jako obszar o dużym potencjale, również biznesowym, ale traktowany odmiennie niż masowe generowanie treści tekstowych, jako produkt o wyższej wartości jednostkowej.
Istotnym wątkiem była także alternatywna analityka i marketing mix modeling. Prelegent otwarcie wskazywał na rosnącą niedokładność klasycznych systemów analitycznych, wynikającą m.in. z problemów z atrybucją i wdrożeniami consent mode. W odpowiedzi na te ograniczenia rozwijane są modele, które pozwalają lepiej zrozumieć realny wpływ poszczególnych kanałów na sprzedaż, nawet przy niepełnych danych.
Całość tej części domykało oczekiwanie na rozwój aplikacji i funkcji transakcyjnych w modelach AI. Zdaniem Łukasza Kacprzaka to właśnie pojawienie się danych o rzeczywistych działaniach użytkowników (zakupach, wydatkach, konwersjach) będzie punktem przełomowym. Dopiero wtedy możliwe stanie się pełniejsze modelowanie, optymalizacja i rozliczanie działań GEO w sposób porównywalny do tego, co dziś znamy z klasycznego SEO.


