 / Artykuły
/ wtorek, 14 października 2025 roku
/ Artykuły
/ wtorek, 14 października 2025 roku
Relacja z Festiwalu SEO 2025

W piątek, 10 października, część zespołu IF.PL wzięła udział w trzynastej edycji Festiwalu SEO – jednego z najważniejszych wydarzeń dla specjalistów zajmujących się pozycjonowaniem i optymalizacją stron internetowych w Polsce. Katowicka konferencja, znana z merytorycznych wystąpień i nieformalnej atmosfery, ponownie przyciągnęła tłumy pasjonatów marketingu w wyszukiwarkach, od doświadczonych ekspertów po osoby stawiające pierwsze kroki w branży.
- Spis treści
- Paradoksy w SEO – Sebastian Heymann
- Czego naprawdę chce Google? Najważniejsze koncepcje z patentów Google’a i ich praktyczne zastosowanie w SEO – Rafał Borowiec
- Audyt SEO, który zostanie przeczytany, a może nawet wdrożony – Szymon Słowik
- Ta domena jest jakaś inna, czyli pułapki rozszerzeń domenowych – Marcin Opolski
- Transformacja największego inhouse’u SEO do hybrydy. Jak i dlaczego wybraliśmy agencję? – Natalia Paciorek i Grzegorz Majchrzak
- Jak rozwijać AI Search bez utraty widoczności w SERP-ach? – Jan Kawecki
- Jak kupować linki w sieci (szybko) – Tomasz Tymiński
- Jak za 2 lata nadal mieć pracę w SEO – Paweł Sokołowski
- I że Cię nie opuszczę aż do… migracji – Milena Fietko
- Dekodując cytowania: jak wygląda DNA Google AI Overview – Maciej Chmurkowski
Tegoroczna edycja Festiwalu obfitowała w inspirujące prelekcje, podczas których wypowiedziano 31 221 słów (nie licząc sesji Q&A). Najczęściej powtarzające się hasła to: Google (100), SEO (94), AI (68), klient (64), domena (58), agencja (49), patent (49), link (37), budżet (35), content (31), semantyka (25), dane (24), wiedza (22), algorytm (20), ranking (18), AIO (AI Overviews) (16), Meta Description (13), reputacja (11), AI Mode (10), PageRank (8), SERP (7), Crawl (6) — co doskonale pokazuje kierunek, w jakim zmierza cała branża.
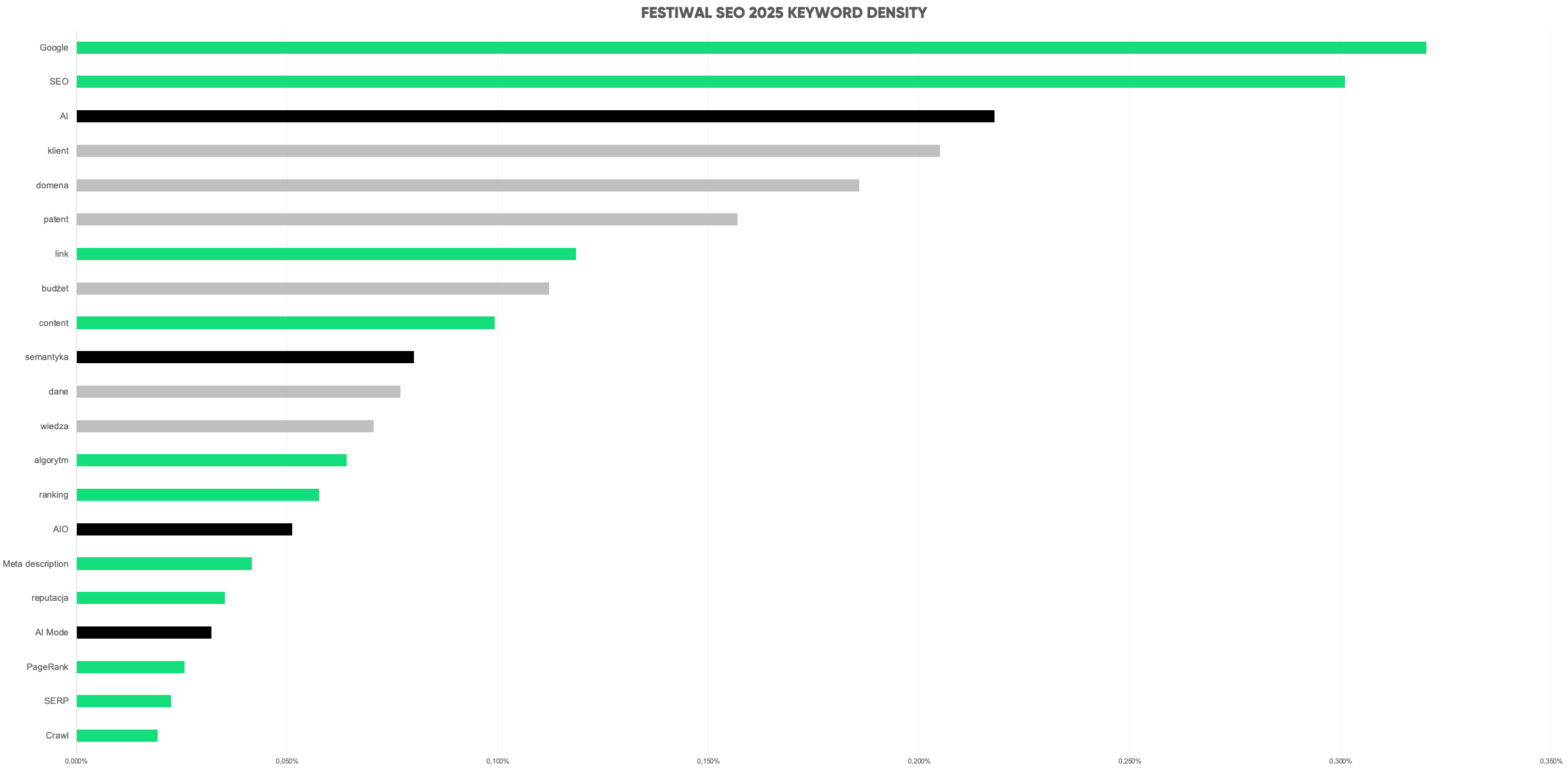
Na scenie wystąpiło 11 prelegentów, prezentując 10 różnorodnych tematów, od analizy patentów Google’a, przez audyty SEO i pułapki rozszerzeń domenowych, aż po zagadnienia związane z przyszłością sztucznej inteligencji w wyszukiwarkach.
Atmosfera Festiwalu tradycyjnie sprzyjała wymianie doświadczeń, rozmowom o nowych trendach oraz refleksji nad przyszłością SEO w erze dynamicznie rozwijającego się AI. Poniżej przedstawiamy szczegółowe omówienie wszystkich prelekcji, które przyciągnęły uwagę uczestników tegorocznego wydarzenia.
Paradoksy w SEO – Sebastian Heymann
Prelekcja Sebastiana Heymanna Paradoksy w SEO była pełnym pasji i doświadczenia wystąpieniem poświęconym zjawiskom w branży SEO, które na pierwszy rzut oka wydają się nielogiczne lub sprzeczne, lecz w praktyce ujawniają, jak naprawdę działają algorytmy Google. Sebastian w charakterystyczny dla siebie sposób – łącząc analityczne podejście z humorem i dystansem – zaprezentował cztery paradoksy, które potrafią diametralnie wpłynąć na efekty pozycjonowania, często wbrew intencjom samych specjalistów SEO. Każdy z nich zaskakuje, skłania do refleksji i pokazuje, że w SEO nie wszystko jest tak oczywiste, jak mogłoby się wydawać.
Prelegent rozpoczął od zjawiska zanieczyszczenia marki (Brand Pollution), które ujawnia, jak generatywne modele AI (np. AIO lub Gemini) mogą błędnie przedstawiać opinie o marce, bazując na nieaktualnych lub mylących źródłach. Następnie przeszedł do omówienia kilku kluczowych paradoksów w SEO – od inflacji wyników, przez wpływ linkowania wewnętrznego, aż po zaskakujące błędy w interpretacji obrazów i paradoks szybkiej indeksacji. Każdy z nich ilustrował realnymi przykładami z projektów agencji Rise360, pokazując, jak nieprzewidywalne bywają wyniki działań SEO mimo poprawnej optymalizacji.
Podsumowując swoje wystąpienie, Sebastian Heymann podkreślił, że SEO jest grą nie tylko z konkurencją, ale i z ograniczeniami samego Google. Zachęcał do uważnej analizy zachowań wyszukiwarki, unikania nadmiernej automatyzacji i świadomego zarządzania reputacją marki w kontekście nowych narzędzi AI.
Zanieczyszczenie marki (Brand Pollution)
Sebastian rozpoczął od lekkiego wprowadzenia i anegdoty o własnym doświadczeniu z wynikami wyszukiwania, które okazały się zanieczyszczone błędnymi informacjami. Zdefiniował pojęcie Brand Pollution jako sytuację, w której marka w wynikach AI Overview (AIO) lub klasycznych wynikach wyszukiwania jest prezentowana w sposób nieprecyzyjny lub błędny. Na kilku przykładach (m.in. Dobre Drzwi, Agnus, Podocenter) pokazał, że systemy AI potrafią pobierać opinie z nieistniejących lub nieaktualnych stron, co prowadzi do błędnych wniosków o reputacji marki. Prelegent podkreślił, że problem ten dotyczy aż 30% analizowanych marek i wezwał słuchaczy do sprawdzania, jak ich firmy są przedstawiane w wynikach AI.
Paradoks 1: Inflacja w SEO
Pierwszym właściwym paradoksem, który omówił Sebastian, była tzw. inflacja w SEO – zjawisko, w którym wyniki pozycjonowania chwilowo przewyższają realną wartość witryny. Prelegent zilustrował to na przykładzie kilku domen, których wykresy widoczności w Google Search Console wykazywały cykliczne górki i wyrównania. Wyjaśnił, że zjawisko to jest skutkiem sposobu, w jaki Google przetwarza zmiany w strukturze linków i atrybutach strony. W pewnych okresach wartości punktowe (rozumiane metaforycznie jako reputacja SEO) są zawyżone, dopóki Google nie przeprowadzi pełnego procesu crawlowania i przetwarzania danych. Dopiero wtedy wyniki „wracają do normy”. Ten paradoks – jak podkreślił Heymann – wynika z ograniczeń infrastrukturalnych Google, który nie jest w stanie jednocześnie crawlować całego internetu.
Paradoks 2: Ukryty potencjał i ryzyka linkowania wewnętrznego
Kolejnym paradoksem, który prelegent omówił, był potencjał linkowania wewnętrznego. Sebastian pokazał, że dobrze zaplanowane linkowanie wewnętrzne może znacząco zwiększyć wartość domeny – bez dodawania nowych treści czy linków zewnętrznych. Jednak ten sam mechanizm działa również w drugą stronę: błędne lub nadmierne linkowanie może powodować spadki i utratę reputacji. Na przykładzie jednego z projektów opisał, jak usunięcie podwójnego menu, zduplikowanej stopki i linków prowadzących do błędów 404 przyniosło wyraźną poprawę wyników. Podkreślił, że linkowanie wewnętrzne to narzędzie o ogromnej sile, które może budować miasta lub je burzyć, a jego skutki bywają wzmocnione przez sygnały użytkowników, które Google uwzględnia w swoich systemach rankingowych.
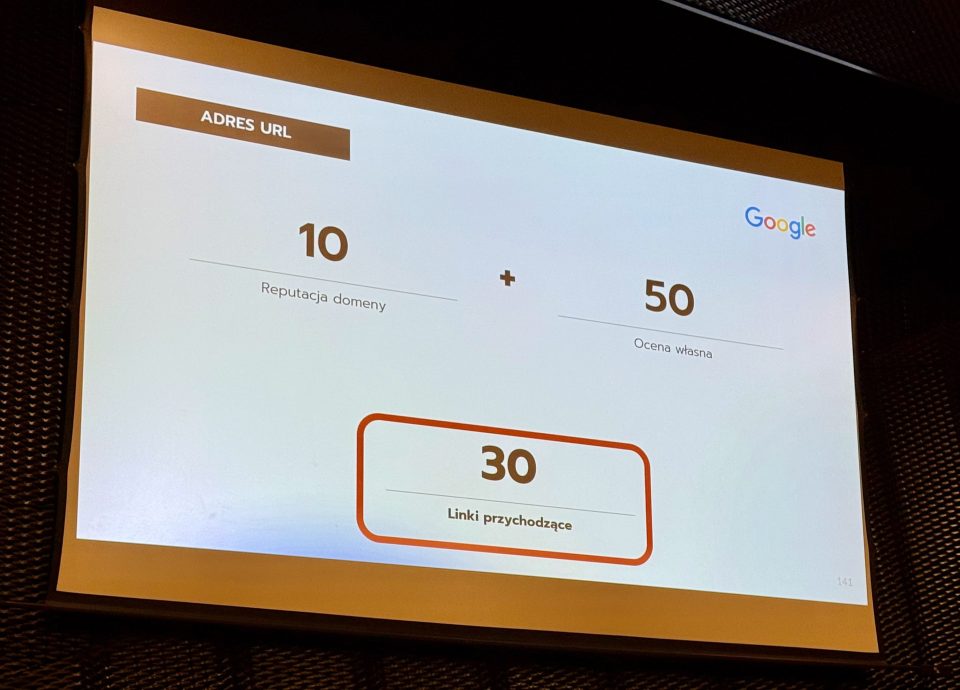
Paradoks 3: Obraz, który nie jest obrazem
W trzecim paradoksie Sebastian poruszył temat błędnej interpretacji obrazów przez Google. Opowiedział anegdotę o swojej stronie głównej, na której – mimo obecności jego zdjęć – w snippetach wyszukiwania pojawiało się zdjęcie innej osoby (Grzegorza Strzelca). Źródłem błędu okazało się użycie znaczników DIV zamiast IMG, przez co Google nie rozpoznawał altów i metadanych obrazów. Heymann wykorzystał ten przykład, aby pokazać, że wyszukiwarka przetwarza tylko określone typy danych (m.in. tagi IMG), a tła i style CSS są pomijane. Dodatkowo zwrócił uwagę, że Google analizuje tekst otaczający obrazy, co wpływa na ich widoczność i kontekst w wynikach AI.
Paradoks 4: Paradoks szybkiej indeksacji
Ostatni paradoks, który omówił Sebastian Heymann, dotyczył szybkiej indeksacji treści. Prelegent przypomniał, że w 2022 roku branża SEO obsesyjnie dążyła do jak najszybszego indeksowania artykułów – przez API, indeksery czy Google Search Console. W efekcie powstała sytuacja, w której strony były indeksowane zanim Google zdążył przeanalizować ich pełny kontekst linków wewnętrznych i zewnętrznych. W konsekwencji treści zyskiwały niepełną reputację i traciły potencjał rankingowy. Heymann nazwał to pułapką indeksacji, podkreślając, że wartość strony ujawnia się dopiero po pełnym procesie crawlowania i przetwarzania wszystkich linków. Jak zaznaczył, nawet dobrze zoptymalizowany artykuł może nie zyskać widoczności, jeśli jego linki nie zostały jeszcze zweryfikowane przez algorytmy.
Podsumowując
W zakończeniu Sebastian Heymann podsumował najważniejsze wnioski z prelekcji:
- należy monitorować sposób, w jaki AI interpretuje markę,
- unikać dynamicznego linkowania, które może prowadzić do niestabilnych wyników,
- wykorzystywać linkowanie wewnętrzne do wykorzystania pełnego potencjału witryny,
- dbać o poprawne wdrażanie obrazów,
- oraz pamiętać, że szybka indeksacja nie zawsze oznacza lepsze wyniki.

Czego naprawdę chce Google? Najważniejsze koncepcje z patentów Google’a i ich praktyczne zastosowanie w SEO – Rafał Borowiec
Rafał Borowiec, znany w branży jako łowca SEO patentów, przedstawił fascynującą analizę tego, jak zrozumienie dokumentów patentowych Google’a może pomóc przewidywać kierunek rozwoju algorytmów wyszukiwarki. Prelegent rozpoczął od przyznania, że większość specjalistów SEO działa reaktywnie — czeka na aktualizacje i próbuje zrozumieć ich skutki — podczas gdy prawdziwe zrozumienie leży w analizie tego, co Google planuje poprzez swoje patenty.
Borowiec przeprowadził uczestników przez historię najważniejszych patentów, które kształtowały rozwój wyszukiwarki – od klasycznego PageRanku po najnowsze technologie AI, takie jak BERT, MUM czy Core Understanding. Pokazał, że śledzenie ewolucji patentów pozwala z dużym wyprzedzeniem przewidywać kolejne zmiany algorytmów, zamiast jedynie reagować na nie po fakcie.
Prelegent podkreślił, że kluczem do sukcesu w SEO staje się dziś umiejętność budowania treści wysokiej jakości, opartych na wiarygodnych źródłach, zrozumieniu intencji użytkownika i wykorzystaniu kontekstowego powiązania między tematami. Jego przesłanie było jasne – Google przestaje być wyszukiwarką słów, a staje się systemem rozumienia informacji.
1. Wstęp i idea przewodnia
Rafał Borowiec rozpoczął od osobistego doświadczenia – przyznał, że przez lata czuł się oszukiwany przez Google, bo każda zmiana algorytmu wydawała się nieprzewidywalna. Z czasem jednak zrozumiał, że zamiast reagować, można przewidywać kierunek zmian, analizując patenty Google’a. Wspomniał też o wycieku Google Leaks z maja 2024 roku, który potwierdził, że większość z 2596 modułów rankingowych i 1414 atrybutów oceny stron była już wcześniej opisana w patentach.
2. Kluczowe patenty i ich znaczenie dla SEO

Prelegent omówił w kolejności ewolucję najważniejszych patentów:
- PageRank – wbrew opiniom, wciąż istotny czynnik; potwierdzony w Google Leaks.
- Information Gain – promujący oryginalne, unikalne treści zamiast kopiowania informacji z TOP10 wyników.
- Query Deserves Freshness (QDF) – mechanizm dynamicznie aktualizujący wyniki dla zapytań dotyczących bieżących wydarzeń.
- Panda – pierwszy duży krok ku analizie całych serwisów i jakości treści; wprowadzenie pojęcia Reference Queries, czyli zapytań brandowych wzmacniających pozycję stron z rozpoznawalną marką.

3. Od PageRanku do semantycznego SEO
Rafał Borowiec przedstawił, jak ewolucja patentów doprowadziła do zmiany sposobu, w jaki Google rozumie świat. Pojawienie się Knowledge Graph zapoczątkowało erę tematycznego SEO, w której wyszukiwarka zaczęła rozpoznawać byty i powiązania między nimi. Z kolei RankBrain, Neural Matching i BERT wprowadziły elementy sztucznej inteligencji, które pozwoliły Google’owi rozumieć znaczenie i kontekst zapytań, a nie tylko słowa kluczowe. W tym momencie zaczęła się era analizy intencji użytkownika.
4. Nowe algorytmy i modularyzacja treści
Patent Passage Ranking (Passage Engine) z 2020 roku wprowadził możliwość oceniania pojedynczych akapitów, co dało przewagę dłuższym, modularnym treściom. Następnie pojawiła się koncepcja E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), która stała się fundamentem oceny jakości stron. Wraz z nią przyszły aktualizacje niszczące tzw. farmy treści i promujące teksty tworzone przez ekspertów.
5. Jakość, wiarygodność i konsensus
Kolejne patenty – m.in. Multisource Expression and Scoring oraz Consensus Scoring – miały na celu eliminację fałszywych informacji. Google zaczął oceniać zgodność treści z ogólnym konsensusem w danej branży. Przykładowo, strony medyczne, które podawały dane sprzeczne z ustalonym standardem, zaczęły tracić pozycje. Dla twórców treści oznacza to konieczność opierania się na rzetelnych źródłach i cytowania autorytetów.
6. Google jako system rozumienia informacji
Wraz z patentem Quality-Based Information Retrieval Google przestał być wyszukiwarką słów, a stał się systemem oceny jakości informacji. Każda branża ma własne wagi czynników – dla newsów liczy się świeżość, dla finansów autorytet, a dla treści longtailowych semantyczna zgodność. W tym kierunku poszedł też patent Core Understanding, w którym wyszukiwarka grupuje zapytania w klastry i analizuje je całościowo, rozumiejąc intencje użytkowników.
7. Dane użytkowników i czynniki behawioralne
Borowiec przytoczył wnioski z wycieków Google Leaks, z których wynika, że Google śledzi każdy klik użytkownika w przedziale od kilku dni do 18 miesięcy. Zwrócił uwagę, że analiza CTR-ów nie wystarcza – Google ocenia satysfakcję użytkownika. Inne czynniki, jak Site Authority, NavBoost czy Quality Score, są złożonymi miarami obejmującymi PageRank, zapytania brandowe, sygnały eksperckości i interakcje z użytkownikiem.
8. Twiddlers i szanse dla małych stron
W końcowej części prelegent przedstawił pojęcie Twiddlers – mechanizmów, które modyfikują wyniki wyszukiwania tuż przed ich wyświetleniem. Jednym z nich jest Smart Personal Site Boost, premiujący mniejsze strony o wysokim poziomie ekspertyzy i autentycznym autorstwie. Dzięki temu małe, specjalistyczne serwisy mogą skutecznie rywalizować z dużymi markami.
9. W kierunku multimodalności i AI
Na koniec Borowiec omówił kierunek, w jakim zmierza Google: integracja treści tekstowych, graficznych i wideo w ramach jednego systemu zrozumienia – zapowiedzianego jeszcze w 2021 roku. Przykładem są już pojawiające się wyniki z Reddita. Dla branży SEO oznacza to konieczność myślenia o treści w sposób kompleksowy i semantyczny, a nie tylko słowami kluczowymi.
10. Jak przewidywać aktualizacje algorytmów
Prelegent pokazał, że niemal każda duża aktualizacja Google’a była poprzedzona publikacją odpowiedniego patentu na 12–18 miesięcy wcześniej. Dzięki analizie dokumentów patentowych można więc z wyprzedzeniem zidentyfikować kierunek zmian. Wspomniał też o narzędziach i źródłach, które ułatwiają analizę patentów:
- https://patents.google.com
- https://www.seobythesea.com
- https://www.kopp-online-marketing.com
- https://searchatlas.com/patentbrain/

Rafał Borowiec zakończył wystąpienie mocnym przesłaniem: Google to nie czarna skrzynka. Wiedza o jego działaniach jest publicznie dostępna – wystarczy zacząć czytać patenty. Zachęcił uczestników, by zamiast ślepo naśladować konkurencję czy opierać się na narzędziach, sami sięgnęli do źródeł. Jak podkreślił – nowoczesne LLM-y ułatwiają analizę patentów jak nigdy wcześniej, a to właśnie tam kryje się przyszłość SEO.
Audyt SEO, który zostanie przeczytany, a może nawet wdrożony – Szymon Słowik
Podczas prelekcji Audyt SEO, który zostanie przeczytany, a może nawet wdrożony Szymon Słowik omówił, jak tworzyć raporty SEO, które nie tylko trafią do klienta, ale faktycznie zostaną przez niego zrozumiane i wdrożone. Prelegent podkreślił, że audyt SEO nie powinien być zbiorem technicznych rekomendacji, lecz dokumentem biznesowym – narzędziem, które pomaga klientowi zarabiać w Google’u. Kluczowe znaczenie ma zrozumienie strategii, celów i możliwości finansowych klienta oraz tworzenie audytu pod kątem jego priorytetów, a nie jedynie wskaźników SEO.
Słowik zwrócił uwagę, że skuteczny audyt wymaga odpowiedniego przygotowania, w tym rozmowy z klientem o marżach, sezonowości, łańcuchu dostaw czy planach rozwoju. Raport powinien być czytelny, zrozumiały i skonstruowany tak, by zachęcał do działania – lepiej przedstawić 20 kluczowych rekomendacji, które zostaną wdrożone, niż 100 punktów, które trafią do szuflady. Prelegent podkreślił także znaczenie właściwego formatowania raportu, jego wizualnej formy i dostosowania języka do odbiorcy.
Na koniec prelegent przypomniał, że audyt SEO powinien być dynamiczny i aktualny – bazować nie na przestarzałych checklistach, lecz na bieżącej wiedzy o algorytmach, intencjach wyszukiwania i zmianach w AI Overviews. Audyt ma być receptą na zarabianie w Google’u, a nie jedynie listą poprawek technicznych.
1. Problem niewdrażanych audytów
Prelegent rozpoczął wystąpienie od zdiagnozowania powszechnego problemu w branży SEO – audyty są wykonywane, ale często nieczytane i niewdrażane. Zwrócił uwagę, że skuteczność audytu nie zależy od liczby punktów w raporcie, lecz od tego, czy jego wnioski przełożą się na realny wynik finansowy klienta. Podkreślił, że celem audytu nie jest poprawa wskaźników SEO, ale ustawienie biznesu klienta w internecie tak, aby generował zysk.
2. Poznanie biznesu klienta
W dalszej części Szymon Słowik omówił znaczenie analizy celów i uwarunkowań biznesowych przed rozpoczęciem audytu. Wskazał, że specjalista SEO powinien wiedzieć, które produkty lub usługi generują najwyższe marże, które kategorie są stabilne, a które sezonowe, oraz jakie są ograniczenia zasobów po stronie klienta. Takie informacje pozwalają dostosować rekomendacje do realnych możliwości wdrożeniowych i uniknąć błędnych priorytetów, np. optymalizowania kategorii o niskiej dostępności lub niewielkim znaczeniu dla przychodów.

3. Raport, który zostanie przeczytany
Kolejny segment poświęcony był formie raportu. Prelegent zapytał retorycznie: 20 czy 100 rekomendacji? – i odpowiedział, że lepszy jest raport krótki, ale skuteczny. Zbyt rozbudowane audyty zniechęcają klientów, powodują paraliż decyzyjny i odkładanie wdrożeń w czasie. Słowik podkreślił, że audyt powinien skupiać się na tzw. short head – kluczowych rekomendacjach o największym wpływie biznesowym, natomiast pozostałe szczegóły można przedstawić w formie suplementu lub backlogu.
4. Filozofia raportowania – Better done than perfect
Prelegent sformułował siedem zasad, które jego zdaniem powinny przyświecać każdemu autorowi audytu SEO. Wśród nich znalazła się zasada better done than perfect – lepszy jest audyt, który zostanie wdrożony, niż perfekcyjny raport pozostający w teorii. Kolejną regułą było dopasowanie języka i zakresu raportu do poziomu wiedzy klienta. Wskazał także na zasadę pareto 20/80 – skupienie się na tych rekomendacjach, które przynoszą największy efekt przy minimalnym nakładzie pracy. Każda rekomendacja powinna być przedstawiona jako konkretne, mierzalne zadanie, a nie ogólnikowy postulat.
5. Priorytetyzacja i storytelling w audycie
Następnie Słowik omówił znaczenie priorytetyzacji rekomendacji – ich oznaczenia według skali ważności (np. 1–5) oraz podziału na must have i nice to have. Zasugerował stosowanie struktury odwróconej piramidy – najważniejsze informacje na początku, a szczegóły dalej. Dobre raporty, jego zdaniem, nie są listą błędów technicznych, lecz opowieścią o SEO z happy endem dla biznesu. W raportach warto przedstawiać dane w kontekście – nie tylko co poprawić, ale dlaczego i jaki przyniesie to efekt finansowy.
6. Formy prezentacji i współpraca z klientem
Prelegent zwrócił uwagę, że sposób prezentacji raportu ma wpływ na to, czy zostanie on wdrożony. PDF to komunikacja jednostronna, podczas gdy Google Docs lub Asana pozwalają włączyć klienta w proces wdrażania. Dodał, że każdy wykres czy dane w raporcie powinny być opatrzone komentarzem, który tłumaczy ich znaczenie i konsekwencje dla biznesu. Raport ma być dokumentem decyzyjnym, a nie zbiorem obrazków.
7. Merytoryczna jakość i aktualność audytów
W końcowym segmencie Słowik podkreślił konieczność stałego aktualizowania wiedzy i narzędzi audytowych. Audytor powinien weryfikować, czy jego rekomendacje są zgodne z aktualnymi zasadami Google, AI Overviews i algorytmami opartymi na uczeniu maszynowym. Zachęcał do analizy patentów Google, testowania hipotez i aktualizacji checklist, by uniknąć błędnych lub nieaktualnych zaleceń. Wskazał też, że SEO coraz częściej wymaga myślenia systemowego i łączenia różnych obszarów – od linkowania wewnętrznego po analizę intencji użytkowników i dane strukturalne.
8. Audyt jako recepta na zarabianie w Google’u
Na zakończenie prelegent podsumował, że audyt SEO nie jest po to, by poprawić stronę pod Google’a, ale po to, by klient zaczął realnie zarabiać. Zachęcił uczestników do odrzucenia mechanicznego podejścia opartego na checklistach na rzecz świadomego, biznesowego myślenia o SEO. Tylko wtedy audyt stanie się nie dokumentem technicznym, lecz narzędziem, które przekłada się na sukces klienta.
Ta domena jest jakaś inna, czyli pułapki rozszerzeń domenowych – Marcin Opolski
Podczas swojej prelekcji Ta domena jest jakaś inna, czyli pułapki rozszerzeń domenowych Marcin Opolski w sposób lekki i przystępny przedstawił złożone zależności pomiędzy rozszerzeniami domen a ich wpływem na SEO, bezpieczeństwo, reputację marki i aspekty techniczne. Na przykładach z historii branży pokazał, że pozornie nieistotne kwestie – jak wybór rozszerzenia domeny – mogą w praktyce prowadzić do realnych problemów biznesowych, od filtrów w Google po blokady mailowe czy nawet utratę domen.
Prelegent rozpoczął od anegdot i przykładów z przeszłości, opisując sytuacje, w których niektóre rozszerzenia domenowe traciły pozycje w wynikach wyszukiwania z powodu spamu lub decyzji Google. Następnie przeszedł do omówienia współczesnych wyzwań: technicznych błędów z subdomenami, problemów antyspamowych, kwestii prawnych i administracyjnych, a także zagrożeń wynikających z niestabilności politycznej czy zmian w międzynarodowych przepisach dotyczących domen.
W końcowej części Marcin Opolski podkreślił, że SEO-wcy powinni zachować czujność wobec pozornie błahych tematów, jak wybór rozszerzenia domeny, ponieważ mogą one mieć konsekwencje zarówno dla widoczności strony, jak i dla całego biznesu. Prelekcję zakończył apelem o wsparcie fundacji PoDrugie.pl, pomagającej młodym osobom w kryzysie bezdomności.
1. Czy rozszerzenie domeny ma znaczenie dla SEO
Marcin Opolski rozpoczął swoją prezentację od pytania, czy rozszerzenie domeny ma znaczenie dla SEO. Zwrócił uwagę, że w branży istnieją dwa dominujące stanowiska: jedni specjaliści uważają, że domena krajowa automatycznie przypisywana jest do rynku danego kraju (np. .pl do Polski), inni zaś twierdzą, że dzięki pracy z treścią i linkami można ten efekt zniwelować. Już na początku prelegent zapowiedział, że jego celem będzie namieszanie w tych opiniach i pokazanie szerszego kontekstu.
2. Historyczne przypadki filtrów i błędów Google
W tej części Marcin Opolski przywołał konkretne wydarzenia z historii SEO. Opowiedział o roku 2011, kiedy wiele domen regionalnych w Polsce zostało objętych filtrem Google i spadło gwałtownie w wynikach wyszukiwania. Podobne zjawiska powtarzały się przynajmniej dwukrotnie w kolejnych latach. Problem dotyczył głównie tanich domen regionalnych, często wykorzystywanych do spamu. Choć Google oficjalnie zaprzeczał lub milczał, po czasie przyznał istnienie błędu.
Prelegent zauważył, że w 2025 roku pojawił się nowy, nietypowy problem z subdomenami .pl — konkretnie pięcioliterowymi (np. example.sklep.pl), które nie mogły zostać poprawnie dodane do Search Console z powodu błędów technicznych.
3. Domeny obarczone ryzykiem antyspamowym
Kolejny segment poświęcony był rozszerzeniom, które mogą powodować problemy z dostarczalnością maili. Marcin Opolski wskazał m.in. na domeny .xyz, .zip i .review, które często są oznaczane przez filtry antyspamowe jako ryzykowne. Przytoczył też dane organizacji Spam House, według których prawie 100% maili z niektórych domen pochodziło ze spamu lub phishingu. Wskazał, że choć te domeny mogą wyglądać atrakcyjnie, to ich użycie może negatywnie wpływać na komunikację firmową.
4. Domeny rozdawane za darmo i ich konsekwencje
Prelegent wspomniał o domenach takich jak .tk, .ga, .cf, .gq czy .cc, które w przeszłości były rozdawane za darmo. Ze względu na nadużycia związane ze spamem, część z nich została zbanowana lub obciążona negatywną historią SEO. W efekcie obecnie nie są rekomendowane do budowania projektów biznesowych.

5. Ciekawostki i mity wokół nazw domen
Marcin Opolski odniósł się do dawnych legend SEO – na przykład przekonania, że cyfry w domenie mogą wzmacniać pozycjonowanie. Choć uznał to za mit, wspomniał, że w wycieku algorytmu Yandexa faktycznie pojawiała się zmienna cyfry w domenie, co świadczy o tym, że takie czynniki bywają uwzględniane w niektórych wyszukiwarkach.
6. Problemy z domenami IDN (ze znakami narodowymi)
W tej części prelegent skupił się na domenach zawierających znaki diakrytyczne, tzw. IDN (Internationalized Domain Names). Wyjaśnił, że choć takie domeny mogą wyglądać atrakcyjnie lokalnie, w praktyce powodują liczne problemy – np. błędy w CMS-ach, komunikatorach, trudności w dyktowaniu adresu czy w generowaniu odnośników. Dodatkowo, systemy mogą przekształcać je w tzw. zapis Unicode, który wygląda nieczytelnie i może odstraszać użytkowników.
7. Domena .io i kwestie prawne
Marcin Opolski omówił popularność domeny .io wśród startupów i jednocześnie zwrócił uwagę na jej niepewny status prawny. Domena ta należy do terytorium zależnego Wielkiej Brytanii, które ma zostać przekazane Mauritiusowi. W związku z tym w przyszłości może zostać wygaszona. Prelegent przytoczył także przykłady historycznych likwidacji domen – takich jak .cs, .ddr, .an czy .su – wynikających ze zmian politycznych i geograficznych.
8. Przypadek domeny .eu i Brexit
Opolski przytoczył przykład Brexitu, kiedy to domeny .eu należące do Brytyjczyków zostały zawieszone. Operator dał im trzy miesiące na wyjaśnienie sytuacji, lecz większość domen nie została odzyskana. Część z nich natychmiast przejęli nowi właściciele. Ten przykład posłużył jako ostrzeżenie, że zmiany polityczne mogą mieć bezpośredni wpływ na utrzymanie domen.
9. Wymagania administracyjne i ograniczenia krajowe
W tej części prelegent omówił wymogi administracyjne dotyczące niektórych rozszerzeń, np. konieczność posiadania obywatelstwa, rezydencji lub lokalnego numeru identyfikacyjnego. Wskazał także na specyficzne ograniczenia – jak w Kazachstanie, gdzie serwery domen muszą znajdować się fizycznie w kraju. Podkreślił znaczenie korzystania z wiarygodnych dostawców oraz sprawdzania regulaminów usług, aby uniknąć utraty domen.
10. Niestabilność polityczna i ryzyka dla SEO
Opolski wskazał na szerszy kontekst ryzyk – od konfliktów zbrojnych po sankcje i problemy z infrastrukturą DNS. Jako przykład podał awarię serwerów DNS w Rosji w 2024 roku, która mogła być skutkiem ataku. Zwrócił uwagę, że właściciele domen powinni brać pod uwagę także ryzyka geopolityczne, które mogą zakłócić dostępność strony.
11. Nowe typy domen i ich ograniczenia techniczne
W tej części Marcin Opolski przedstawił problem nowych rozszerzeń, takich jak .shop, .agency, .online. Choć wyglądają nowocześnie, to starsze wersje przeglądarek i nieaktualizowane CMS-y mogą ich nie rozpoznawać. Prelegent zalecił wybieranie domen, które funkcjonują na rynku co najmniej od roku i testowanie ich w różnych środowiskach.
12. Domeny z emoji – kreatywne, ale problematyczne
Opolski opisał domeny z emoji (np. 😊.pl), używane niegdyś przez duże marki jak Coca-Cola czy Burger King. Wskazał, że mimo atrakcyjności wizualnej są one bardzo trudne w obsłudze technicznej – nie wszystkie serwery je akceptują, mogą powodować błędy w wysyłce maili, różnie się wyświetlają na urządzeniach i są podatne na phishing.
13. Zastosowanie praktyczne i podsumowanie
W końcowej części prelekcji prelegent wskazał, że wiedza o pułapkach rozszerzeń domenowych przydaje się w kontekście ekspansji zagranicznej, brandingu, skracania linków i budowania zapleczy SEO. Podkreślił, że SEO-wcy powinni być świadomi ryzyk i przygotowani na nieoczekiwane problemy.
Na zakończenie zaapelował do uczestników, by wsparli fundację PoDrugie.pl, pomagającą młodym osobom wychodzić z kryzysu bezdomności. Tym samym symbolicznie połączył świat technologii i biznesu z realną pomocą społeczną.
Transformacja największego inhouse’u SEO do hybrydy. Jak i dlaczego wybraliśmy agencję? – Natalia Paciorek i Grzegorz Majchrzak
Podczas prelekcji Transformacja największego inhouse’u SEO do hybrydy. Jak i dlaczego wybraliśmy agencję? Natalia Paciorek i Grzegorz Majchrzak z X-komu przedstawili kulisy procesu przetargowego, w którym ich zespół — dotąd działający wyłącznie in-house — zdecydował się na współpracę z zewnętrzną agencją SEO. Prelegenci opowiedzieli o motywacjach, trudnościach, a także o wnioskach płynących z kontaktu z ośmioma różnymi agencjami. Ich wystąpienie miało charakter szczery, praktyczny i momentami humorystyczny, a celem było podzielenie się z agencjami perspektywą klienta.
Centralnym punktem wystąpienia była analiza czynników, które zadecydowały o wyborze agencji: szczerości, zaangażowania, dopasowania do potrzeb biznesowych oraz umiejętności budowania relacji. Natalia i Grzegorz zwracali uwagę, że przetarg SEO to proces, który przypomina randkowanie — chodzi o wzajemne poznanie, zaufanie i autentyczność, a nie o sprzedaż na siłę.
Na koniec prelegenci przyznali się również do własnych błędów po stronie klienta, takich jak zbyt długi czas reakcji, brak jasno określonego budżetu czy problemy z przekazywaniem danych. Całość zakończyli refleksją, że skuteczna współpraca między in-house’em a agencją opiera się nie tylko na wiedzy eksperckiej, lecz przede wszystkim na zaufaniu, empatii i zrozumieniu wspólnych celów.
Kontekst i geneza przetargu
Natalia Paciorek i Grzegorz Majchrzak rozpoczęli wystąpienie od przedstawienia okoliczności, które doprowadziły do decyzji o współpracy z agencją SEO. Jako przedstawiciele X-komu, firmy z czterema oddziałami i rozbudowanym działem in-house, podkreślili, że wcześniej nie prowadzili przetargów SEO. Współpracę z agencją uznali za potrzebną ze względu na dodatkowe zasoby, świeże spojrzenie i wyzwanie rzucone zespołowi wewnętrznemu.
Prelegenci przedstawili także kontekst biznesowy: spadek widoczności portalu technologicznego Geex i konieczność przeniesienia działań contentowych na główną domenę X-komu. Zmieniono strukturę zakładki poradników, wprowadzono autorów i daty publikacji, a wyniki tych działań — wzrost widoczności i powrót do Google Discover po dwóch latach — potwierdziły skuteczność nowego podejścia.
Powody poszukiwania agencji i początki procesu
Grzegorz Majchrzak opisał trzy główne przyczyny decyzji o poszukiwaniu agencji:
- potrzebę wsparcia operacyjnego,
- chęć uzyskania zewnętrznej perspektywy,
- wyjście z własnej bańki elektromarketu.
X-kom chciał zweryfikować swoje działania, wprowadzić świeże pomysły i zyskać partnera, który będzie umiał spojrzeć na SEO w szerszym, biznesowym kontekście. Natalia Paciorek dodała, że proces przetargowy rozpoczęto z ośmioma agencjami, a każda z nich wniosła coś wartościowego. Zespół postanowił nie tworzyć rankingu najlepszych ofert, lecz dopasować potrzeby firmy do kompetencji poszczególnych agencji. Ten etap prelegenci opisali metaforycznie jako agencyjny Tinder, gdzie najważniejsza była szczerość i umiejętność słuchania.

Lekcje z procesu przetargowego – pozytywne obserwacje
Prelegenci szczegółowo omówili dobre praktyki, które pozytywnie wyróżniły niektóre agencje. Największe wrażenie zrobiła szczerość jednej z firm, która zrezygnowała z udziału w przetargu, uznając, że optymalizacja strony nie przyniesie już znaczących efektów. Takie podejście zbudowało zaufanie i pokazało profesjonalizm.
Innym ważnym elementem była otwartość na spotkania na żywo. Natalia i Grzegorz zauważyli, że w świecie zdominowanym przez komunikację online osobisty kontakt nadal ma ogromne znaczenie. Spotkania, podczas których agencje więcej słuchały niż mówiły, pozwalały klientowi poczuć się zrozumianym i zaopiekowanym.
Prelegenci podkreślili też znaczenie stabilności zespołu w agencji — niska rotacja pracowników to sygnał bezpieczeństwa dla klienta planującego długoterminową współpracę.
Patrzenie szerzej niż SEO
Grzegorz Majchrzak zwrócił uwagę, że tylko jedna agencja zapytała o szerszy kontekst działań X-komu — kampanie wizerunkowe, dostępność towaru, planowane wdrożenia. Tymczasem takie pytania mają ogromny wpływ na estymacje wyników i strategię SEO.
Cenne było także to, gdy agencje potrafiły zauważyć coś więcej — np. wpływ aplikacji mobilnej na ruch organiczny czy niedosyt treści wideo względem konkurencji. Takie obserwacje pokazywały prawdziwe zrozumienie biznesu.
Dodatkowo, agencje, które wyprzedzały obawy in-house’u, zdobywały przewagę. Prelegenci wysoko ocenili postawy zespołów, które deklarowały współpracę i edukowanie pracowników X-komu zamiast prób przejęcia ich obowiązków.
Sfera finansowa i różnice w podejściu do budżetu
Jednym z kluczowych wątków była polityka cenowa. Prelegenci zauważyli ogromne różnice w ofertach — od kilku do kilkudziesięciu tysięcy złotych przy identycznym briefie. Ich zdaniem mogło to wynikać z wykorzystania przez niektóre agencje narzędzi AI i automatyzacji procesów, co realnie obniża koszty.
Natalia Paciorek podkreśliła jednak, że zbyt wczesne pytania o budżet mogą zniechęcać, jeśli klient nie jest jeszcze na tym etapie gotowy. Z kolei Grzegorz zauważył, że zrozumiałe jest, iż agencje potrzebują tej informacji, dlatego rekomendował model trzech wariantów — minimum, optimum i maksimum — lub przedstawianie budżetowych widełek.
Czego unikać – błędy po stronie agencji
W drugiej części wystąpienia prelegenci przeszli do omówienia błędów, które najczęściej popełniały agencje.
Najpoważniejszym z nich był brak dopasowania poziomu merytorycznego do odbiorcy — część zespołów tłumaczyła podstawowe pojęcia SEO specjalistom z wieloletnim doświadczeniem.
Innym błędem była zbyt duża liczba specjalistów na spotkaniu, co prowadziło do chaosu i braku spójności komunikacji. Natalia i Grzegorz rekomendowali, aby podczas pierwszego kontaktu obecny był dobrze przygotowany handlowiec, który potrafi prowadzić rozmowę i koordynować wypowiedzi techniczne ekspertów.
Wspomnieli również o zbyt wczesnych deklaracjach współpracy (będziemy się chwalić na LinkedInie), niejasnych lub upiększonych ofertach oraz próbach dosprzedaży usług, których klient nie potrzebował. Dla prelegentów ważna była transparentność i prostota oferty — najlepiej w dwóch wersjach: krótkiej (dla zarządu) i rozszerzonej (dla menedżerów).
Błędy po stronie klienta
Pod koniec wystąpienia Natalia i Grzegorz przyznali, że również X-kom nie był bez winy. Po stronie klienta problemem był brak jasno określonego budżetu, ograniczony dostęp do danych (GA, Search Console, dane księgowe), a także długie czasy reakcji.
Zachęcili agencje, aby w takich sytuacjach cisnęły klienta — wyznaczały deadline’y i przypominały się o odpowiedziach, bo często brak reakcji nie wynika ze złej woli, a z przeciążenia obowiązkami.
Współpraca oparta na zaufaniu
Na zakończenie prelegenci podkreślili, że udany przetarg SEO przypomina proces budowania relacji — oparty na szczerości, empatii i zrozumieniu, a nie tylko na technicznych umiejętnościach. Jak podsumowali, najważniejsze w przetargu jest wzbudzenie zaufania i poczucia bezpieczeństwa – często nawet bardziej niż sama ekspertyza.
Dla uczestników przygotowali również checklistę dla agencji z konkretnymi radami.
Jak rozwijać AI Search bez utraty widoczności w SERP-ach? – Jan Kawecki
Podczas swojego wystąpienia Jak rozwijać AI Search bez utraty widoczności w SERP-ach Jan Kawecki z agencji Chili Fruit Web Consulting poruszył temat zmian, jakie wprowadza rozwój wyszukiwarek opartych na sztucznej inteligencji. Prelegent wskazał, że tradycyjne SEO — oparte na linkach, blogpostach i klasycznych frazach kluczowych — coraz częściej ustępuje miejsca podejściu, w którym kluczową rolę odgrywają brand mentions, świeżość treści oraz logiczne klastry tematyczne.
Kawecki podkreślił, że w erze AI Search widoczność w klasycznych wynikach SERP nadal pozostaje istotna, jednak równocześnie należy budować obecność w wynikach generowanych przez modele językowe i systemy typu AI Overviews. Według niego kluczem jest umiejętne połączenie tych dwóch światów — poprzez odpowiedni dobór treści, ich struktury oraz dystrybucji.
W drugiej części wystąpienia prelegent zaprezentował praktyczne wskazówki, jak tworzyć i promować treści tak, by skutecznie pojawiać się w AI Search. Omówił m.in. znaczenie aktualności publikacji, sposoby taniego zdobywania brand mentions oraz wykorzystanie parasite SEO i klastrowania tematycznego jako strategii zwiększania szans na pojawienie się w wynikach generowanych przez LLM-y.
1. Zmiana kierunku w SEO
Jan Kawecki rozpoczął swoje wystąpienie od krótkiego wprowadzenia i interakcji z publicznością. Wyjaśnił, że jego celem jest pokazanie, jak połączyć widoczność w klasycznych wynikach wyszukiwania z widocznością w AI Search. Podkreślił, że przez AI rozumie szeroko — od AI Overviews i AI Mode po czaty oparte na dużych modelach językowych, takich jak ChatGPT.
Zaznaczył, że w ostatnich latach zaszła istotna zmiana — jeszcze niedawno kluczowe były klasyczne blogposty, dziś coraz większe znaczenie mają listingi i rankingi (np. top 5, top 10), które lepiej wpisują się w sposób, w jaki AI przetwarza treści.
2. Różnice między SEO a AI Search
Prelegent omówił różnice między tym, jak użytkownicy formułują zapytania w Google, a tym, jak rozmawiają z czatami AI. W klasycznym wyszukiwaniu dominują krótkie frazy (tzw. short tail), natomiast w czatach – dłuższe, opisowe pytania.
Zwrócił uwagę na to, że w AI Search duże znaczenie ma autorytet źródła — stąd świetne wyniki Wikipedii czy Reddita, które dostarczają jasnych, konkretnych odpowiedzi. W tradycyjnym SEO liczyły się głównie linki, natomiast w AI Search większą rolę odgrywają brand mentions – wzmianki o marce bez linków, które budują jej kontekst i wiarygodność.
3. Pozycjonowanie treści – pięć kluczowych zasad
Jan Kawecki przedstawił zestaw pięciu praktycznych zasad skutecznego pozycjonowania treści pod kątem AI Search:
- Zawsze bądź numerem jeden – w rankingach i zestawieniach własna marka powinna zajmować pierwsze miejsce, by zwiększyć szansę na bycie zindeksowanym i cytowanym.
- Wybieraj konkurencję z głową – do zestawień warto dobierać marki, które nie konkurują bezpośrednio (np. z innych rynków lub segmentów).
- Ton wypowiedzi – w treściach należy pisać wprost, używając sformułowań typu ChiliFruit is the best, gdyż algorytmy nie analizują kontekstu psychologicznego.
- My i tamci – prelegent podkreślił znaczenie powtarzania nazwy własnej marki w tekście, przy jednoczesnym unikaniu wzmacniania konkurencji.
- Świeżość treści – Kawecki zwrócił uwagę, że w AI Search najlepiej radzą sobie artykuły aktualizowane regularnie, nawet co miesiąc. Dodał żartobliwie, że nieaktualizowanie roku w rankingach to grzech kardynalny.
4. Widzialni i zaufani – rola treści poza własną domeną
W kolejnej części prelegent wyjaśnił różnicę między byciem widzialnym a zaufanym źródłem.
Zaufane źródła to te, z których AI pobiera informacje bezpośrednio (np. cytowane w AI Overviews). Widzialne źródła to natomiast wszelkie inne miejsca, gdzie marka jest wzmiankowana. Kawecki podkreślił, że własny blog to za mało – kluczowe jest pojawianie się w różnych publikacjach zewnętrznych. W tym kontekście nawiązał do zjawiska parasite SEO, które – mimo wcześniejszych zapowiedzi Google o jego eliminacji – powróciło i może być skutecznie wykorzystywane do budowania zasięgu.
5. Klastrowanie treści i loteria AI Search
Kawecki porównał AI Search do loterii – każda wzmianka o marce to los w puli, zwiększający szansę na pojawienie się w odpowiedziach AI.
Podkreślił wagę klastrowania tematycznego – publikowania wielu treści wokół jednego, ściśle zdefiniowanego tematu, zamiast rozpraszania się na różne obszary. Powołując się na dane z narzędzia Surfer, wskazał, że większość wyników wyszukiwania (nawet 90%) można przypisać do kilku głównych klastrów tematycznych.
Na przykładzie kampanii klienta z branży e-mail marketingu pokazał, jak powielanie kluczowego motywu w wielu publikacjach zewnętrznych (z drobnymi różnicami w tytule) doprowadziło do częstego pojawiania się marki w odpowiedziach AI.
6. Jak działać przy ograniczonym budżecie
Prelegent zwrócił uwagę, że rozbudowane działania link-buildingowe i wpisy gościnne są kosztowne. Alternatywą mogą być tańsze brand mentions.
Przedstawił metodę reverse engineeringu: najpierw należy zebrać listę słów kluczowych i przeprowadzić symulacje wyników AI Search o różnych porach dnia, by zidentyfikować powtarzające się, zaufane domeny. Następnie można do nich kierować outreach – prośby o dodanie wzmianki w już istniejących artykułach.
Kawecki dodał, że taki text edit może być dużo tańszy niż pełny link czy guest post, a wciąż przynosi efekty. Najlepiej, jeśli wzmianka ma kilka linijek i zawiera dwa wystąpienia nazwy marki, co ułatwia AI zrozumienie kontekstu.
7. Mierzenie efektów
Na zakończenie Jan Kawecki wskazał narzędzia, które pomagają monitorować widoczność marki w AI Search, takie ChatBeat. Zalecił, by po wdrożeniu kampanii brand mentions obserwować, czy wzrasta częstotliwość pojawiania się firmy w odpowiedziach AI.
Podkreślił, że w wielu branżach (szczególnie poza finansową i medyczną) efekty są widoczne już po kilkunastu wzmiankach. Jego zdaniem połączenie klasycznego SEO z działaniami w AI Search pozwala osiągnąć wysoką widoczność przy niższych kosztach niż tradycyjny guest posting.
Jak kupować linki w sieci (szybko) – Tomasz Tymiński
Podczas prelekcji Jak kupować linki w sieci (szybko) Tomasz Tymiński zaprezentował praktyczne i nowoczesne podejście do link buildingu w kontekście zmian zachodzących w wyszukiwarce Google, zwłaszcza pojawienia się AI Overviews. Prelegent skoncentrował się na tym, jak skutecznie inwestować w publikacje, by zwiększyć ich szansę na cytowanie przez systemy oparte na sztucznej inteligencji oraz jak optymalizować proces zakupu linków, aby był szybszy, bardziej efektywny i bezpieczny.
Tymiński podzielił wystąpienie na trzy główne obszary: przyszłość (czyli wpływ AI Overviews na SEO), teraźniejszość (czyli sposoby na przyspieszenie codziennej pracy związanej z link buildingiem) oraz pułapki i manipulacje (czyli jak unikać błędnych decyzji i nierzetelnych danych w procesie wyboru portali). Jego prezentacja miała charakter zarówno edukacyjny, jak i praktyczny – opierała się na konkretnych analizach, danych oraz przykładach z narzędzi, które zespół prelegenta wdrożył w praktyce.
Na zakończenie Tymiński podkreślił trzy kluczowe wnioski: konieczność podejmowania szybszych decyzji strategicznych opartych na danych, przyspieszenie działań operacyjnych dzięki automatyzacji oraz skuteczną weryfikację portali, które mają wpływ na jakość linków i widoczność witryn w wyszukiwarce.
Przyszłość link buildingu – AI Overviews
W pierwszej części prelekcji Tomasz Tymiński skupił się na zjawisku AI Overviews (AIO) – nowym formacie prezentacji wyników wyszukiwania przez Google. Przedstawił badania przeprowadzone na bazie ponad miliona polskich fraz, które pozwoliły opracować wskaźnik AIO Rating. Jest to logarytmiczna miara określająca, jak często dana domena jest cytowana w wynikach AIO. Dla kontekstu prelegent wskazał, że Wikipedia osiąga poziom 100, natomiast popularny portal PoradnikPrzedsiębiorcy.pl – 85.
Analiza wykazała, że treści najczęściej pojawiające się w AIO są dłuższe i bardziej wyczerpujące, a największy wpływ na obecność w wynikach mają portale tematyczne. Publikacje na nich mają nawet dziesięciokrotnie większą szansę na cytowanie przez AIO niż treści z portali ogólnych lub lokalnych.

Tymiński przedstawił też rozwiązanie oparte na kategoriach AI Overviews, które pozwala precyzyjnie identyfikować witryny tematyczne oraz analizować, jakich fraz dotyczy większość cytowań. Uczestnicy poznali również narzędzie umożliwiające wyszukiwanie domen pojawiających się w AIO dla konkretnych słów kluczowych, co znacznie ułatwia planowanie publikacji.
Podsumowując ten segment, prelegent zwrócił uwagę na trzy najważniejsze wnioski:
- Portale tematyczne mają znacząco większy potencjał w kontekście AIO.
- AIO Rating można traktować jako nową formę DR-ki dla AI.
- Tematyczność według wydawcy nie zawsze odpowiada temu, jak postrzega ją Google.
Jak robić to samo szybciej – automatyzacja i optymalizacja procesu
Drugi segment wystąpienia dotyczył usprawnienia codziennej pracy przy zakupie linków. Tymiński przedstawił rozwiązania pozwalające skrócić czas wyboru portali, dodawania wytycznych i raportowania nawet kilkunastokrotnie na platformie LinkHouse. Omówił nowy interfejs bazy ofert, który umożliwia personalizowane wyszukiwanie domen, filtrowanie wyników według dopasowania tematycznego i parametrów SEO oraz automatyczne zapisywanie konfiguracji filtrów. Wprowadzenie funkcji wish list pozwala z kolei planować publikacje z wyprzedzeniem, grupując je w projekty miesięczne lub kwartalne.
W kwestii tworzenia wytycznych prelegent podkreślił, że największym pożeraczem czasu jest ręczne przygotowywanie briefów. Nowe rozwiązanie umożliwia hurtowe dodawanie treści i elementów wizualnych w systemie drag and drop, co skraca proces z kilkudziesięciu minut do kilku. Z kolei w obszarze raportowania Tymiński zaprezentował funkcję generowania w pełni personalizowanych raportów – dopasowanych do klienta, projektu lub agencji – z możliwością automatycznego wyboru danych i eksportu gotowych zestawień.
Jak nie wpaść w pułapki – weryfikacja danych i unikanie manipulacji
Ostatni fragment prelekcji był poświęcony błędom i manipulacjom, które często pojawiają się przy ocenie wartości portali. Tymiński omówił najczęstsze pułapki, takie jak sztucznie zawyżony Domain Rating (DR) czy fałszowany ruch organiczny. Zwrócił uwagę, że parametry SEO powinny być analizowane łącznie – jeśli jeden z nich nie rozmawia z innymi, może to być sygnał ostrzegawczy. Prelegent zaprezentował nową funkcję w LinkHouse, umożliwiającą analizę historycznego wykresu DR oraz wgląd w najpopularniejsze podstrony i słowa kluczowe bezpośrednio z poziomu platformy.
Podkreślił też, że sam wysoki DR nie gwarantuje wartości portalu, a nienaturalne skoki wskaźników często wynikają z manipulacji. Z kolei w kontekście ruchu organicznego należy zwracać uwagę, czy nie pochodzi on z mało wartościowych fraz lub z jednego źródła. Warto również sprawdzać kraj pochodzenia ruchu, zwłaszcza przy działaniach na rynkach zagranicznych.
Zakończenie
Tomasz Tymiński zakończył prelekcję trzema podsumowującymi wnioskami:
- Szybsze decyzje strategiczne – dzięki danym o AIO i tematyczności można planować skuteczniejsze działania.
- Szybsze działania operacyjne – automatyzacja procesów znacząco skraca czas pracy.
- Szybsza weryfikacja portali – nowe narzędzia pozwalają unikać błędów i manipulacji.
Prelegent podkreślił, że wszystkie omawiane rozwiązania wynikają z rozmów z agencjami SEO i specjalistami in-house, zachęcając uczestników do dalszej wymiany doświadczeń i sugestii.
Jak za 2 lata nadal mieć pracę w SEO – Paweł Sokołowski
Paweł Sokołowski w swojej prelekcji Jak za 2 lata nadal mieć pracę w SEO podjął temat gwałtownych zmian w branży SEO spowodowanych rozwojem sztucznej inteligencji. Wystąpienie miało charakter ostrzegawczy, ale i motywujący – prelegent pokazał, że mimo niepewności związanej z wprowadzeniem AI Mode i AIO, przyszłość SEO nie jest przesądzona, o ile specjaliści są gotowi na intensywną naukę i transformację zawodową.
Sokołowski przeanalizował ewolucję SEO – od czasów klasycznych, przez semantyczne, aż po nadchodzącą erę AI SEO. Podkreślił, że branża stoi przed przełomem, który może z dnia na dzień zmienić sposób działania wyszukiwarek i narzędzi, a wiele znanych dziś ról zawodowych w SEO przestanie istnieć lub przejdzie gruntowną transformację.
W drugiej części wystąpienia prelegent wskazał konkretne kierunki rozwoju i umiejętności, które staną się kluczowe w nowych realiach: praca z modelami AI, nadzór nad sztuczną inteligencją, analiza danych, zarządzanie wiedzą i prompt engineering. Zakończył wystąpienie apelem o odwagę w adaptacji do zmian i ciągłe doskonalenie, podkreślając, że przyszłość branży zależy od gotowości do nauki.
1. Wprowadzenie i diagnoza branży
Paweł Sokołowski rozpoczął od refleksji nad kondycją branży SEO – jej nieprzewidywalnością, presją ciągłych zmian i potrzebą nieustannej nauki. Zwrócił uwagę, że wiele osób pracujących w SEO poświęca znacznie więcej czasu niż standardowe godziny pracy, a mimo to codziennie mierzy się z niepewnością. Branża, jego zdaniem, przypomina rollercoaster, który przyspiesza coraz bardziej – a punkt, do którego zmierza, staje się coraz mniej jasny.
2. Ewolucja SEO: od klasycznego do AI SEO
Prelegent przedstawił ewolucję SEO w trzech etapach: klasyczne SEO (lata 2010–2020), semantyczne SEO i obecne przejście do ery AI SEO. Okres klasycznego SEO charakteryzował się przewidywalnością algorytmów i istnieniem licznych ścieżek na skróty. Semantyczne SEO przyniosło większy nacisk na treść i jej znaczenie. Obecny etap – związany z AI Mode – to rewolucja, w której Google może z dnia na dzień zmienić lub wyeliminować całe obszary analizy danych, a wyniki organiczne mogą zniknąć z wyników wyszukiwania. To, jak zauważył Sokołowski, zmienia nie tylko metody pracy, ale też sposób budowania ofert i rozliczania się z klientami.
3. Brak stabilnych narzędzi i nowe wyzwania
W trzeciej części Sokołowski omówił problem niedostosowania obecnych narzędzi do nowych realiów. Wskazał, że budowa narzędzi SEO wymaga stabilności rynku, której obecnie brakuje. Nowe narzędzia będą musiały wykorzystywać AI, a ich rozwój wymusi od specjalistów ogromną inwestycję w wiedzę techniczną. Prelegent podkreślił, że nadchodzące lata będą wymagały intensywnego dokształcania – szacunkowo nawet pięciu–sześciu lat nauki w ciągu dekady, co oznacza poświęcenie wielu weekendów i wieczorów.
4. Transformacja zawodów SEO
Ten segment stanowił serce prelekcji. Paweł Sokołowski zaprezentował analizę transferu zawodowego – czyli mapowania obecnych ról w SEO na ich odpowiedniki w świecie AI. Część zawodów, jak link building, może zostać przekształcona w działania PR-owe lub oparte na wzmiankach, a inne – szczególnie rutynowe – po prostu znikną. Równocześnie pojawią się nowe zawody związane z nadzorem, analizą danych czy fact-checkingiem AI. Branża będzie podzielona na dwa obszary: ekspertów nadzorujących sztuczną inteligencję oraz osoby o niższych kwalifikacjach, wspierające automatyzację procesów.

5. Rola edukacji, odporności i analityki
Sokołowski zaznaczył, że w nowym świecie SEO kluczowe będą trzy cechy: głód wiedzy, odporność psychiczna i umiejętność analizy danych. Podkreślił, że analityka stanie się fundamentem pracy – codzienny feedback i obserwacja efektów działań będą decydować o sukcesie. Wskazał także, że w czasach AI specjaliści SEO muszą stać się partnerami dla maszyn, rozumiejąc mechanizmy działania modeli językowych i sposób, w jaki AI przetwarza dane.
6. Znaczenie narzędzi i semantyki
W kolejnej części Paweł Sokołowski omówił rolę semantyki i narzędzi w nowym SEO. Pokazał, jak rozwiązania jego zespołu – m.in. Contadu i Neuron Writer – wykorzystują sztuczną inteligencję do rekomendowania treści na poziomie fragmentów tekstu. Wyjaśnił znaczenie passage indexing i konieczność tworzenia treści w logicznych blokach (chunkach), które AI może łatwiej interpretować i cytować. Semantyka, jego zdaniem, staje się absolutnym fundamentem nowoczesnego pozycjonowania.
7. Nowe role i kompetencje w SEO
W tej części Sokołowski szczegółowo przedstawił nowe role zawodowe:
- Content specialist AI – osoba, która łączy umiejętność pisania z kompetencjami prompt engineeringu.
- Technical SEO expert – specjalista od architektury informacji i grafów wiedzy.
- Link building & mentions manager – ekspert od wzmiankowania i budowania autorytetu marki.
- Data scientist – analityk danych tworzący i utrzymujący ekosystem wiedzy w firmie.
- SEO Strategy Director – nowa rola odpowiedzialna za definiowanie strategii AI i komunikacji z klientem.
Prelegent podkreślił, że przyszłość SEO wymaga interdyscyplinarności – połączenia kompetencji językowych, technicznych, analitycznych i strategicznych.
8. Mechanizmy działania AI i znaczenie wiedzy technicznej
W końcowym fragmencie wystąpienia Sokołowski przedstawił uproszczony schemat działania systemów AI: od tworzenia embeddingów, przez łączenie fragmentów wiedzy (chunków), po generowanie odpowiedzi w AI Mode czy AI Overview. Wyjaśnił, jak dane z różnych źródeł – Shopping Graph, Knowledge Graph czy wideo – są integrowane przez modele językowe. Podkreślił, że każdy SEO-wiec powinien rozumieć ten proces, ponieważ decyduje on o tym, w jaki sposób AI ocenia i prezentuje treści.
9. Zakończenie
Na zakończenie Paweł Sokołowski zachęcił słuchaczy, by nie bali się zmian. Z humorem porównał przyszłość SEO-wców i hydraulików – obie grupy mają przed sobą wyzwania, ale tylko ci, którzy będą się rozwijać i dostosowywać, zachowają swoje miejsce na rynku. Zakończył słowami o sile determinacji i ciągłej nauki, które staną się kluczowe w nowej, zdominowanej przez AI rzeczywistości.
I że Cię nie opuszczę aż do… migracji – Milena Fietko
Podczas prelekcji I że Cię nie opuszczę aż do migracji Milena Fietko w niezwykle szczery i autoironiczny sposób opowiedziała o jednej z najbardziej problematycznych migracji SEO w swojej karierze. Zamiast typowej prezentacji o sukcesach, prelegentka skupiła się na porażce – projekcie, który mimo dobrych intencji i doświadczenia zakończył się znacznymi spadkami widoczności i licznymi błędami technicznymi. Jej celem było pokazanie, że nawet najlepsi specjaliści popełniają błędy, a otwarte mówienie o nich może stanowić cenną lekcję dla całej branży.
Milena porównała proces migracji do małżeństwa – pełnego emocji, zaangażowania, ale też ryzyka nieporozumień i rozczarowań. Na przykładzie współpracy z luksusowym sklepem jubilerskim pokazała, jak brak komunikacji między biznesem, zespołem deweloperskim i SEO prowadzi do katastrofalnych skutków. Opowiedziała krok po kroku, jak z pozornie prostego projektu narodził się toksyczny związek SEO, pełen frustracji, chaosu i konieczności gaszenia pożarów.
Prelekcja zakończyła się refleksją nad rolą komunikacji, planowania i wzajemnego zrozumienia między zespołami. Fietko podkreśliła, że sukces migracji zależy nie tylko od kompetencji technicznych, ale przede wszystkim od umiejętności współpracy. Jej przesłanie było proste, ale mocne: SEO i development muszą się kochać, a biznes nie zawsze ma rację – choć zawsze ma ostatnie słowo.
Między małżeństwem a migracją
Milena rozpoczęła swoją prezentację od zaskakującej analogii – porównała proces migracji strony internetowej do małżeństwa. Przywołując statystyki rozwodowe, zwróciła uwagę, że podobnie jak w relacjach między ludźmi, także w SEO około 30% migracji kończy się niepowodzeniem. W ten sposób zbudowała metaforyczny kontekst dla swojego wystąpienia, pełnego humoru i dystansu do własnych błędów.
Prelegentka podkreśliła, że jej celem nie jest zaprezentowanie kolejnego case study o sukcesie, lecz szczere opowiedzenie o porażce – projekcie, który mimo doświadczenia i zaangażowania nie przyniósł oczekiwanych rezultatów. Już na tym etapie zapowiedziała, że jej historia będzie spowiedzią SEO-wca, z której każdy uczestnik może wyciągnąć praktyczne wnioski.
Etap I: przygotowania do migracji – ignorowane sygnały ostrzegawcze
Pierwszy etap, nazwany przez Milenę fazą przygotowań do katastrofy, ukazał, jak wiele błędów można popełnić jeszcze przed startem projektu. Fietko przyznała, że zlekceważyła tzw. red flagi: brak harmonogramu, niejasną komunikację między biznesem, PM-em i developerami oraz presję szybkiego wdrożenia nowej wersji strony.
Klient – luksusowy sklep jubilerski – chciał osiągnąć poziom marek takich jak Cartier czy Tiffany, ale nie był gotowy na skalę technologicznego przedsięwzięcia. SEO zostało włączone do projektu zbyt późno, a system nie posiadał żadnych funkcjonalności optymalizacyjnych. Milena przyznała, że był to jej pierwszy klient na freelansie, przez co zbyt mocno zaufała zapewnieniom zespołu deweloperskiego. W efekcie już na starcie pojawiły się braki w audycie starej strony, niejasne priorytety i brak integracji między potrzebami SEO, UX i biznesu.
Etap II: faza migracyjna – chaos i niekontrolowane wdrożenie
Kolejny segment dotyczył samego momentu migracji, który – jak się okazało – odbył się bez wiedzy Mileny. Prelegentka z humorem przytoczyła sytuację, gdy dowiedziała się o planowanym uruchomieniu nowej strony z wiadomości na Slacku – zaledwie dzień przed planowanym startem. Mimo sprzeciwu klient nalegał na publikację, twierdząc, że gorzej już być nie może.
Skutki tej decyzji były dramatyczne. Strona wystartowała bez mapy witryny, pliku robots.txt, poprawnych przekierowań i canonicali. Pojawiły się błędy 404, duplikacje treści, błędna paginacja i adresy URL generowane wielokrotnie w oparciu o breadcrumbs. Zabrakło wersji angielskiej, altów dla zdjęć i optymalizacji nazw produktów. Milena żartobliwie wspomniała, że część tych altów musiała wprowadzać ręcznie – łącznie ponad 20 tysięcy. Ten etap prelegentka określiła krótko: poszło nie tak wszystko, co mogło pójść nie tak.
Etap III: łatanie błędów – desperacka walka o naprawę
Po migracji rozpoczął się etap gaszenia pożarów. Zespół deweloperski miał inne priorytety niż SEO – skupiał się na naprawie koszyka i funkcji zakupowych, ignorując błędy optymalizacyjne. Milena musiała walczyć o każdą poprawkę, często słysząc, że SEO wymyśla problemy. W efekcie poprawki były wprowadzane chaotycznie i bez wcześniejszej weryfikacji, co tylko pogłębiało problemy z indeksacją.
Jednym z najbardziej kuriozalnych błędów był sposób, w jaki developerzy próbowali zamaskować błędy 404, zwracając na froncie kod 200 – przez co w logach wyglądało, jakby wszystko działało poprawnie. Mimo częściowych napraw (jak wdrożenie mapy witryny i poprawienie kilku kategorii), widoczność strony nie poprawiła się. Prelegentka otwarcie przyznała, że efekty były żadne – strona wciąż notowała spadki.
Etap IV: terapia – nauka, komunikacja i współpraca
Ostatni etap Milena określiła mianem terapii. Pomimo wszystkich problemów, współpraca z klientem nie została zakończona. Zamiast tego obie strony skupiły się na odbudowie zaufania, poprawie komunikacji i edukacji. Ustalono zasady współpracy z zespołem deweloperskim i opracowano sposób konsultacji każdej zmiany pod kątem SEO.
Fietko zakończyła prelekcję refleksją: w procesie migracji kluczowe jest nie tylko doświadczenie, ale też ustalenie harmonogramu, jasnych celów i wzajemnego szacunku. SEO musi być obecne od samego początku projektu, a komunikacja z developerami powinna być partnerska, nie konfrontacyjna. Jej końcowe przesłanie brzmiało: SEO plus dev muszą się kochać. I nie bójmy się mówić o błędach.
Dekodując cytowania: jak wygląda DNA Google AI Overview – Maciej Chmurkowski
Podczas swojej prelekcji Maciej Chmurkowski przedstawił wyniki autorskiego badania mającego na celu zrozumienie, dlaczego Google AI Overviews (AIO) cytuje jedne strony, a inne pomija. W oparciu o analizę setek wyników i dziesiątek cech stron internetowych, prelegent odsłonił wzorzec, który jego zdaniem stanowi swoiste DNA cytowań w nowym ekosystemie wyszukiwania opartym na sztucznej inteligencji.
Chmurkowski wskazał, że kluczowe znaczenie mają czynniki semantyczne i strukturalne — nie tylko techniczne SEO. AI Google szuka wiedzy eksperckiej, umiaru emocjonalnego w języku oraz treści logicznie rozwiniętych od ogółu do szczegółu. Jednocześnie prelegent obalił popularne mity SEO, takie jak nadmierne nasycanie słowami kluczowymi czy stawianie na clickbait.
Podsumowując swoje wystąpienie, Maciej Chmurkowski podkreślił, że era AI Mode nie oznacza końca dla twórców treści, lecz wymusza nową precyzję i świadomość językową. To dane — a właściwie ich struktura — stanowią dziś kod genetyczny wyszukiwania.
Wprowadzenie i kontekst rewolucji AI
Prelegent rozpoczął wystąpienie od refleksji na temat przemian w świecie technologii i wyszukiwarek. Porównał współczesny moment w branży SEO do przełomowych odkryć naukowych, takich jak zdefiniowanie struktury DNA przez Watsona i Cricka w 1953 roku. Tak jak wówczas, dziś również stoimy — jak zauważył — u progu rewolucji, ale nie do końca rozumiemy jej natury. W centrum tej zmiany znajduje się AI oraz system Google AI Overviews, który redefiniuje sposób prezentowania i cytowania treści.
Chmurkowski zwrócił uwagę, że niepokój, który budzi rozwój AI wśród specjalistów SEO, wynika z braku zrozumienia mechanizmów działania modeli i algorytmów. Dlatego jego celem było zdekodowanie tych procesów — czyli odkrycie, jakie cechy treści decydują o tym, że są cytowane przez Google.
Metodologia badania
Prelegent przedstawił szczegółowo sposób, w jaki przeprowadził analizę. Na początku zebrał słowa kluczowe, dla których miał stuprocentową pewność, że generują odpowiedź w AI Overviews. Następnie zbudował bazę danych, w której przypisał każdemu słowu odpowiadające mu cytowane adresy URL.
Kolejnym krokiem było stworzenie grup porównawczych — stron cytowanych i niecytowanych, ale wysoko pozycjonowanych w organicznych wynikach wyszukiwania. Z obu grup pobrano treści, a następnie przetworzono je w oparciu o 54 różne cechy, w tym elementy semantyczne, strukturalne i techniczne. Chmurkowski opracował również autorską metrykę separation score, która pozwalała określić, jakie cechy najbardziej różnicują obie grupy stron.
Kluczowe wyniki i interpretacje
Największą różnicę między stronami cytowanymi a niecytowanymi wykazała głębokość zagłębienia adresu URL — Google preferuje treści pochodzące z podstron eksperckich, a nie z kategorii czy stron głównych. Kolejnym odkryciem była rola meta description i meta title. Strony cytowane charakteryzowały się wysokim podobieństwem semantycznym między tymi elementami a odpowiedzią AI, co sugeruje, że Google najpierw analizuje sekcję HEAD, zanim przejdzie do pełnej treści strony.

Znaczenie miały także encje i ich zgodność z tematem odpowiedzi. Im większe pokrycie encji w treści, tym większa szansa na cytowanie. Zaskoczeniem okazał się fakt, że zbyt szybkie udzielanie bezpośredniej odpowiedzi nie zwiększało szans na cytowanie — lepiej działało stopniowe wprowadzenie od ogółu do szczegółu. Z kolei teksty o wyraźnym nacechowaniu emocjonalnym były częściej pomijane, ponieważ Google preferuje neutralne, wyważone źródła wiedzy.
Wnioski praktyczne i implikacje dla SEO
Na podstawie zebranych danych Chmurkowski zaproponował kierunek zmian w podejściu do SEO i tworzenia treści. Zalecił, by twórcy koncentrowali się na semantyce, logicznej strukturze oraz naturalnym języku pozbawionym przesadnego marketingowego tonu. Zamiast sztucznego nasycania frazami, należy dbać o powiązania między pojęciami i zgodność semantyczną tytułu, opisu i treści z intencją zapytania.
Prelegent zapowiedział także rozwinięcie projektu badawczego — planuje stworzyć model predykcyjny, który będzie w stanie obliczyć prawdopodobieństwo cytowania danej strony w AI Overviews. Model miałby analizować dane wejściowe, takie jak słowo kluczowe, odpowiedź AI oraz treść strony, i generować wynik wraz z rekomendacjami optymalizacyjnymi.
Spojrzenie w przyszłość
W końcowej części wystąpienia Maciej Chmurkowski podkreślił, że AI Mode nie stanowi zagrożenia, lecz naturalny etap ewolucji wyszukiwarek. Ze względu na wysokie koszty przetwarzania danych, tryb ten nie będzie dominował, a cytowania nadal pozostaną selektywne. Zachęcił uczestników, by zamiast panikować, skupili się na doskonaleniu meta title i description oraz na rozwijaniu eksperckich treści o neutralnym tonie.
Maciej zakończył prelekcję refleksją: tak jak DNA definiuje życie, tak struktura danych definiuje widoczność w wyszukiwarce. To właśnie dane, semantyka i ich relacje stanowią dziś prawdziwe DNA współczesnego SEO.


