Crawler (inaczej: robot indeksujący, web spider, web crawler, web bot) to program komputerowy, którego głównym zadaniem jest przeglądanie, indeksowanie i odnajdywanie informacji na stronach internetowych. Automatycznie przeszukuje linki, analizuje zawartości stron i zapisuje informacje w bazie danych.
Jak działa crawler?
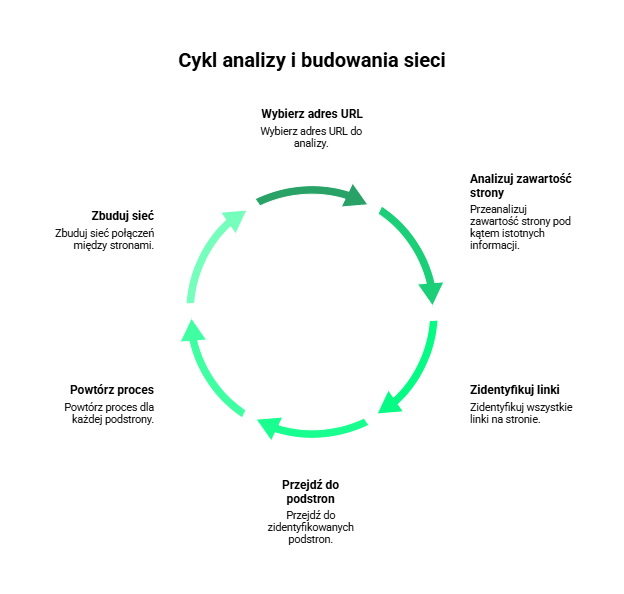
Proces działania crawlera rozpoczyna się od wybrania konkretnego adresu URL (ang. Uniform Resource Locator). Następnie program analizuje zawartość wybranej strony internetowej, wyodrębniając z niej linki do innych podstron i witryn. Po zidentyfikowaniu tych linków, crawler przechodzi przez nie, powtarzając proces dla każdej napotkanej strony i tworząc między nimi sieć połączeń. Działanie to umożliwia wyszukiwarkom internetowym odnajdywanie i indeksowanie ciągle powstających w internecie podstron.
Identyfikacja robota indeksującego
Odwiedzając stronę internetową, crawler przedstawia się określonym User-Agentem, który ma postać ciągu tekstowego, różniącego się w zależności od danego programu lub bota. W przypadku Googlebota jest to m.in.:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Natomiast wyszukiwarka Bing może przedstawiać się poniższym User-Agentem:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)Ruch sieciowy a roboty
Według dostępnych danych na stronie Statista, około 40% całkowitego ruchu w internecie generowane jest przez różne rodzaje botów i crawlerów. Statystyka ta wskazuje, że znaczna część aktywności online nie pochodzi od interakcji użytkowników, lecz jest wynikiem działania automatycznych programów komputerowych, które przeszukują, analizują lub wchodzą w interakcje z zasobami dostępnymi w sieci.


